index
La Novitade
Section titled “La Novitade”Qlevergate
Section titled “Qlevergate”QLever’s data structures for the original triples are highly compressed and optimized for query processing. The data structures for the update triples are currently less optimized. The performance difference is negligible when the number of update triples is small compared to the number of original triples, but it becomes significant when there are many update triples. (https://docs.qlever.dev/rebuild-index/)
| Fase | Tempo per file (su 43 file) |
|---|---|
| collect_identifiers | 340-490s |
| storage | 150s → 1623s |
collect_identifiers resta stabile (nel suo fare schifo). storage cresce drammaticamente.
To rebuild the index efficiently, QLever provides the command qlever rebuild-index, which directly rebuilds the index from the existing data structures. With a Ryzen 9 9950X (16 cores) and NVMe SSD, this takes less than one minute for 500 million triples.
Ho realizzato che rebuild-index ha una complessità che non è lineare al numero di triple aggiunte, ma alla dimensione totale dell’indice. Impiega meno che ricostruire l’indice da zero. ma impiega comunque più dei 1623 secondi cioè 20 minuti. Di conseguenza è impensabile ricostruire l’indice ogni mille righe e allo stesso tempo è impensabile aggiornare QLEVER tramite query SPARQL.
Ho eseguito dei benchmark per trovare la miglior combinazione tra numero di ID all’interno di una query SPARQL su Qlever e numero di query in contemporanea. e ho trovato che l’ideale è avere 30 ID in una query con 25 query in contemporanea.
perf(curator): parallelize identifier collection for large CSVs
Add ProcessPoolExecutor-based parallel processing for the identifier extraction phase when row count exceeds min_rows_parallel threshold.
perf(cleaner): replace iterative replace() calls with str.translate()
Use precomputed translation tables for hyphen and space normalization. This reduces O(n*k) string operations to O(n) where k is the number of characters to normalize.
refactor: unify entity storage with EntityStore and prefix MetaIDs
Introduces EntityStore class that combines entity data storage, merge tracking (Union-Find), and bidirectional identifier lookups. Replaces separate brdict, radict, idbr, idra dictionaries with a single unified store.
perf(finder): replace rdflib Graph with dict-based triple store
ResourceFinder stored triples in an rdflib Graph (local_g) and maintained per-subject Graph copies in prebuilt_subgraphs. Both structures carry substantial overhead from rdflib's indexing and object allocation.
Replace them with plain dicts: _spo (subject -> predicate -> [objects]) and _po_s (predicate+object -> {subjects}). All query methods now use dict lookups instead of Graph.triples() iteration. The get_subgraph method reconstructs an rdflib Graph on demand for oc_ocdm compatibility.
This also removes the everything_everywhere_allatonce Graph from Curator and the local_g parameter from ResourceFinder's constructor.
- Artemis II è crashata a causa di doi.org/10.36962/doi:10.36962/ecs107/3-5/2025-14. Un DOI col prefisso doi: incluso nel DOI. Il mio codice rimuoveva il prefisso a un certo punto, senza prevedere la possibilità che il prefisso fosse parte del valore letterale.
if identifier.startswith(br_id_schema): identifier = identifier.replace(f"{br_id_schema}:", "")if identifier.startswith(f"{br_id_schema}:"): identifier = identifier.split(":", 1)[1]refactor!: switch check_results output from text report to structured JSON
The text report was not machine-readable, making it unusable by pipeline orchestrators. Output is now a JSON file with status (PASS/FAIL), per-file stats, errors, and warnings. Exit code 1 on errors, 0 otherwise.
BREAKING CHANGE: output format changed from plain text to JSON
perf(finder): batch VVI queries with SPARQL VALUES clauses
Replace individual per-VVI SPARQL queries with batched VALUES queries grouped by pattern (issue+volume, issue-only, volume-only). This reduces the number of round-trips to the triplestore. Also track and display the max traversal depth reached during subgraph resolution.
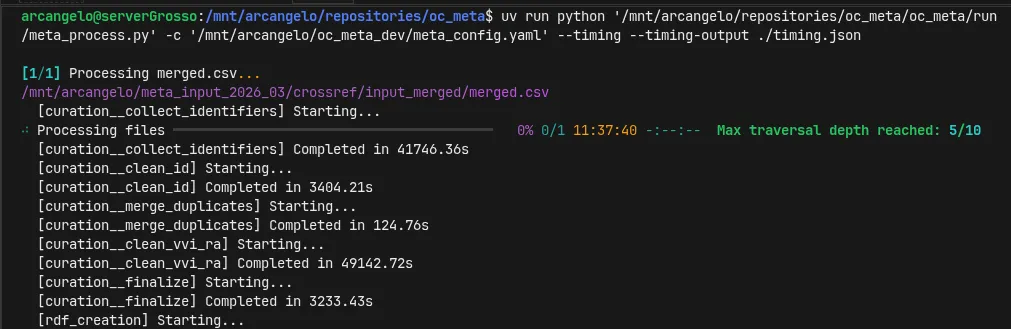
27 ore per la fase di curatela relativa a 2.7 milioni di righe di CSV. Ottimo che la massima ricorsione raggiunta nello scoprire nuovi soggetti di cui recuperare il grafo sia quella attesa
oc_ds_converter
Section titled “oc_ds_converter”fix(crossref): skip citing entities without DOI references
RAMOSE
Section titled “RAMOSE”
feat: port oc_api improvements to upstream ramose
Backport four changes that diverged in oc_api's local copy of ramose.py:
- use raw strings for all regex patterns (Python 3.12+ DeprecationWarning)
- use persistent requests.Session with 60s timeout for SPARQL queries
- add endpoint_override parameter to APIManager constructor
- add optional html_meta_description support in generated documentation
build!: migrate from poetry to uv and update python support
Bump supported Python versions from 3.7-3.10 to 3.10-3.13.
Fix store_documentation to unpack the tuple returned by get_documentation. Fix duplicate closing brace in CSS. Add guard in clean_log for malformed log lines. Move logging import to module level.
BREAKING CHANGE: minimum Python version raised from 3.7 to 3.10
test: replace stale API checks with local meta integration tests
The old tests depended on external APIs that no longer return responses.
Add integration tests backed by a local OpenCitations Meta dataset served through QLever, and update CI/CD to run pytest with coverage, publish the coverage badge, and trigger releases.
LOL 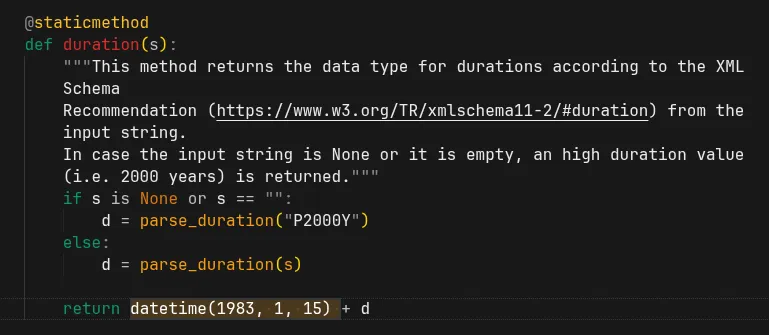
https://opencitations.github.io/ramose/coverage/
https://github.com/opencitations/oc_api/pull/32
feat: add multi-source SPARQL, SPARQL Anything, OpenAPI export, and pluggable formats
Based on: opencitations/ramose#20 and the extensions-feature branch.
Co-authored-by: Sergey Slinkin
chore: set up REUSE 3.3 license compliance
oc_ocdm
Section titled “oc_ocdm”fix(graph)!: make res_type a required parameter in GraphEntity
res_type was incorrectly defaulting to None despite being mandatory for every entity. Swap parameter order so res_type comes before the optional res, update all GraphSet factory methods accordingly, and modernize type annotations throughout both modules.
BREAKING CHANGE: GraphEntity.init signature changed — res_type is now the third positional argument (required), res is fourth (optional).
refactor(graph): fix type annotations and restructure merge as template method
Replace merge method overrides across the entity hierarchy with a template method pattern to resolve typing violations.
GraphEntity.merge now uses Self for the other parameter, enforces same-type checking at runtime via short_name comparison, and delegates property-specific merging to _merge_properties hooks that subclasses implement instead of overriding merge directly.
Ogni sottoclasse di entity sovrascriveva merge per aggiungere la propria logica di copia delle proprietà. Il metodo merge usa Self come tipo del parametro other, perchè il merge ha senso solo tra entità dello stesso tipo. Il punto è che quando una sottoclasse sovrascrive un metodo e ne restringe il tipo di un parametro, sta violando il principio di sostituzione di Liskov:
Se q(x) è una proprietà che si può dimostrare essere valida per oggetti x di tipo T, allora q(y) deve essere valida per oggetti y di tipo S dove S è un sottotipo di T
un BibliographicResource.merge che accetta solo BibliographicResource è più restrittivo di GraphEntity.merge che accetta qualsiasi GraphEntity. Pyright segnalava ogni singolo override come errore.
Soluzione
Section titled “Soluzione”merge è definito una sola volta in GraphEntity. Si occupa della parte fissa dell’algoritmo (quella che vale per tutti i tipi di entity) e delega il lavoro specifico a un hook _merge_properties, che le sottoclassi implementano al posto di sovrascrivere merge.
Lo scheletro di merge:
GraphEntity.merge(other: Self)
1. verifica che other.short_name == self.short_name2. redireziona le triple che puntavano a other verso self3. risolve rdf:type (con la logica di prefer_self)4. copia la label5. aggiorna i flag di merge e la merge list6. segna other come da cancellare7. chiama self._merge_properties(other, prefer_self)Ogni sottoclasse sovrascrive solo _merge_properties. La catena di super()._merge_properties() fa sì che ogni livello della gerarchia contribuisca con la sua parte, dal piu’ generale al più specifico.
GraphEntity.merge confronta other.short_name con self.short_name e lancia TypeError se non corrispondono. Questo sostituisce i decoratori @accepts_only che prima stavano su ogni override di merge nelle sottoclassi: un unico punto di controllo al posto di dodici sparsi nella gerarchia.
Domande
Section titled “Domande”Migrazione index da setuptools a uv
Section titled “Migrazione index da setuptools a uv”Attualmente setup.py esegue queste operazioni al momento dell’import:
- Crea la directory ~/.opencitations/index/logs/
- Copia config.ini e lookup.csv nella home dell’utente
Con pyproject.toml non è possibile eseguire codice arbitrario durante l’installazione. Vorrei capire cosa sono quei file prima di procedere.

shacl-extractor
Section titled “shacl-extractor”https://github.com/skg-if/shacl-extractor/issues/4
feat: generate sh:in for controlled vocabulary properties
Support the {prefix:val1 prefix:val2 ...} syntax in dc:description annotations to declare a fixed set of allowed named individuals. The extractor emits sh:in with an rdf:List of IRIs instead of sh:class or sh:node. Both prefixed names and absolute IRIs are accepted inside the braces.
Release immutabili
Section titled “Release immutabili”
Ho attivato le release immutabili su tutti i repository dell’organizzazione opencitations su GitHub
Licenze
Section titled “Licenze”Se io genero un file SHCL automaticamente utilizzando un software a partire da un file OWL che ha una certa licenza, Il file generato, quale licenza avrà?
Ramose
Section titled “Ramose”C’è una ragione per cui ramose è un unico file di 1000 e passa righe?
- Time agnostic library
- Workshop
Aldrovandi
-
Ai related works c’è da aggiungere l’articolo su chad kg Vizioso
-
https://en.wikipedia.org/wiki/Compilers:_Principles,_Techniques,_and_Tools
-
HERITRACE
- C’è un bug che si verifica quando uno seleziona un’entità preesistente, poi clicca sulla X e inserisce i metadati a mano. Alcuni metadati vengono duplicati.
- Se uno ripristina una sotto entità a seguito di un merge, l’entità principale potrebbe rompersi.
-
Meta
- Bisogna rigenerare il DOI ORCID Index
- Matilda e OUTCITE nella prossima versione
- Da definire le sorgenti
- Va su Trello
- Bisogna produrre la tabella che associa temp a OMID per produrre le citazioni.
-
OpenCitations
- Rilanciare processo eliminazione duplicati
- trovare tutti quelli che ci usano
-
“reference”: { “@id”: “frbr:part”, “@type”: “@vocab” } → bibreference
-
“crossref”: { “@id”: “biro:references”, “@type”: “@vocab”} → reference
-
“crossref”: “datacite:crossref”
-
oc_ocdm
- Automatizzare mark_as_restored di default. è possibile disabilitare e fare a mano mark_as_restored.
-
https://opencitations.net/meta/api/v1/metadata/doi:10.1093/acprof:oso/9780199977628.001.0001
-
DELETE con variabile
-
Modificare Meta sulla base della tabella di Elia
-
embodiment multipli devono essere purgati a monte
-
Modificare documentazione API aggiungendo omid
-
Heritrace
- Per risolvere le performance del time-vault non usare la time-agnostic-library, ma guarda solo la query di update dello snapshot di cancellazione.
- Ordine dato all’indice dell’elemento
- date: formato
- anni: essere meno stretto sugli anni. Problema ISO per 999. 0999?
- Opzione per evitare counting
- Opzione per non aggiungere la lista delle risorse, che posso comunque essere cercate
- Configurabilità troppa fatica
- Timer massimo. Timer configurabile. Messaggio in caso si stia per toccare il timer massimo.
- Riflettere su @lang. SKOS come use case. skos:prefLabel, skos:altLabel
- Possibilità di specificare l’URI a mano in fase di creazione
- la base è non specificare la sorgente, perché non sarà mai quella iniziale.
- desvription con l’entità e stata modificata. Tipo commit
- display name è References Cited by VA bene
- Avvertire l’utente del disastro imminente nel caso in cui provi a cancellare un volume
-
Meta
- Fusione: chi ha più metadati compilati. A parità di metadato si tiene l’omid più basso
- Issue github parallelizzazione virtuoso
- frbr:partOf non deve aggiungere nel merge: https://opencitations.net/meta/api/v1/metadata/omid:br/06304322094
- API v2
- Usare il triplestore di provenance per fare 303 in caso di entità mergiate o mostrare la provenance in caso di cancellazione e basta.
-
RML
- Vedere come morh kgc rappresenta database internamente
- https://github.com/oeg-upm/gtfs-bench
- Chiedere Ionannisil diagramma che ha usato per auto rml.
-
Crowdsourcing
- Quando dobbiamo ingerire Crossref stoppo manualmente OJS. Si mette una nota nel repository per dire le cose. Ogni mese.
- Aggiornamenti al dump incrementali. Si usa un nuovo prefisso e si aggiungono dati solo a quel CSV.
- Bisogna usare il DOI di Zenodo come primary source. Un unico DOI per batch process.
- Bisogna fare l’aggiornamento sulla copia e poi bisogna automatizzare lo switch