2026-03-19 Peffomance
La Novitade
Section titled “La Novitade”oc_ds_converter
Section titled “oc_ds_converter”@pytest.fixture(params=["redis", "sqlite", "inmemory"])def storage_manager(request: pytest.FixtureRequest, tmp_path): if request.param == "redis": sm = RedisStorageManager(testing=True) elif request.param == "sqlite": sm = SqliteStorageManager(str(tmp_path / "test.db")) else: sm = InMemoryStorageManager(str(tmp_path / "test.json")) yield sm sm.delete_storage()feat(storage): restore SqliteStorageManager and InMemoryStorageManager
- Add parametrized pytest fixture to test all three storage managers (redis, sqlite, inmemory) with single test code
- Redis remains the default storage manager

Update ROR id manager
- updated RORManager.syntax_ok() with more correct (restrictive) regex
- extended the RORManager class to make its behaviour more similar to the one of ORCIDManager (as concerns the possibility to use multiple storage managers)
- added tests for RORManager, which were missing (new testing functions and related data)
Cose non cose
Section titled “Cose non cose”if isinstance(item['container-title'], list): ventit = str(item['container-title'][0])https://api.crossref.org/works/10.1007/978-3-030-00668-6_8
"container-title": [ "Lecture Notes in Computer Science", "The Semantic Web – ISWC 2018"]Secondo me bisognerebbe concatenare, non selezionare il primo
RaProcessor (base generica) | +-- CrossrefStyleProcessing (nuova - logica comune citing/cited) | | | +-- CrossrefAdapter (parsing JSON Crossref) | +-- JalcAdapter (parsing JSON JALC) | +-- PubmedProcessing (resta separato) +-- DataciteProcessing (resta separato)refactor: extract shared logic into CrossrefStyleProcessing base class
Extract common processing infrastructure from CrossrefProcessing and JalcProcessing into a new CrossrefStyleProcessing abstract base class. Move shared utility functions to process_utils.py.
Align jalc_process.py with crossref_process.py processing pattern.
refactor: make Redis opt-in and share publisher lookup logic
Move publisher lookup by DOI prefix into CrossrefStyleProcessing base class so both Crossref and JALC processors can use it. This also adds CSV fallback for JALC when Redis is not available.
Redis usage is now controlled explicitly via --use-redis flag instead of being implicitly required. Default behavior uses in-memory storage, which works for single-threaded processing. Multiprocessing still requires Redis and the CLI now warns when attempting to use multiple workers without it.
Il Giapporcid
Section titled “Il Giapporcid”Io non ci credo che i Giapponesi non usino gli ORCID
data = json.load(zf.open(json_file))content_str = json.dumps(data).lower()
has_orcid_field = 'orcid' in content_strhas_orcid_value = bool(ORCID_PATTERN.search(content_str))┏━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┓┃ Metric ┃ Value ┃┡━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━┩│ Total ZIP files │ 2,792 ││ Total JSON files │ 9,847,719 ││ Files with 'orcid' field │ 380,667 ││ Files with ORCID values │ 380,661 ││ Unique ORCID values │ 4,353 ││ ZIPs containing ORCIDs │ 217 ││ % with 'orcid' field │ 3.8655% ││ % with ORCID values │ 3.8655% │ { "sequence": "2", "type": "person", "names": [ { "lang": "en", "last_name": "LIN", "first_name": "Weiren" } ], "affiliation_list": [ { "sequence": "1", "affiliation_name_list": [ { "affiliation_name": "京都大学", "lang": "ja" }, { "affiliation_name": "Kyoto University", "lang": "en" } ], "affiliation_identifier_list": [ { "affiliation_identifier": "https://ror.org/02kpeqv85", "type": "ROR" } ] } ], "researcher_id_list": [ { "id_code": "http://orcid.org/0000-0003-3228-2789", "type": "ORCID" } ] }feat(jalc): extract ORCID from researcher_id_list in creator metadata
Tutto molto bello, e i publisher? In JALC in teoria non dovrei trovare nessun prefisso di Crossref. Vediamo.
| Categoria | Record | Percentuale |
|---|---|---|
| Totale record analizzati | 9.840.132 | 100% |
| Match (nome uguale) | 5.014 | 0,1% |
| Mismatch (nome diverso) | 17.702 | 0,2% |
| Prefisso non in mapping Crossref | 9.817.416 | 99,8% |
| Prefisso | Nome Crossref | Nome JALC | Record |
|---|---|---|---|
| 10.1241 | Japan Science and Technology Agency (JST) | Japan Science and Technology Agency | 15.478 |
| 10.18934 | Wiley | The Japanese Society for Dermatoallergology and Contact Dermatitis, The Japanese Society for Cutaneous Immunology and Allergy | 126 |
| 10.5834 | Japanese Society for Dental Health | Japanese Society for Oral Health | 2.098 |
10.1241 (differenza: manca “(JST)” nel nome JALC):
- 10.1241/johokanri.27.79
- 10.1241/johokanri.12.63
- 10.1241/johokanri.21.902
10.18934 (Wiley vs società giapponese - probabile acquisizione/cambio editore):
- 10.18934/jedca.11.3_215
- 10.18934/jscia.3.2_299
- 10.18934/jedca.11.2_154
10.5834 (differenza: “Dental Health” vs “Oral Health”):
- 10.5834/jdh.53.3_188
- 10.5834/jdh.49.2_151
- 10.5834/jdh.40.287
JALC non ha un equivalente dell’endpoint /members di Crossref.
JALC: /prefixes restituisce solo prefix, ra, siteId, updated_date
{ "prefix": "10.11107", "ra": "JaLC", "siteId": "SI/JST.JSTAGE", "updated_date": "2024-01-15" }refactor!(jalc): remove publisher prefix mapping
JALC is a separate DOI registration agency from Crossref and has no equivalent /members API endpoint to provide authoritative publisher names. Analysis showed 99.8% of JALC prefixes are not in the Crossref mapping. Publisher names are now taken directly from the source data's publisher_list field.
BREAKING CHANGE: JalcProcessing no longer accepts publishers_filepath or use_redis_publishers parameters. The -p/--publishers CLI argument has been removed from jalc_process.py.
I fixi su rimozione entità già presenti in Meta e duplicati in ds_converter sembrano funzionare. In futuro, dovrei mettere nel ds_converter anche la gestione del numero di righe dei file CSV, in modo da poter cancellare lo script di preprocessing di Meta in toto.
(oc-meta) arcangelo@serverGrosso:/mnt/arcangelo/repositories/oc_meta$ uv run '/mnt/arcangelo/repositories/oc_meta/oc_meta/run/meta/preprocess_input.py' /mnt/arcangelo/meta_input_2026_03/jalc/input/ /mnt/arcangelo/meta_input_2026_03/input_preprocessed --redis-port 6390 --rows-per-file 1000 --workers 16Found 2349 CSV files to process with 16 workers Filtering existing IDs ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 2349/2349 0:01:08 0:00:00 Deduplicating and writing ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 2349/2349 0:00:14 0:00:00 Processing Report┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┓┃ Metric ┃ Value ┃┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━┩│ Total input files processed │ 2349 ││ Total input rows │ 2489489 ││ Rows discarded (duplicates) │ 0 ││ Rows discarded (existing IDs) │ 0 ││ Rows written to output │ 2489489 ││ │ ││ Duplicate rows % │ 0.0% ││ Existing IDs % │ 0.0% ││ Processed rows % │ 100.0% │└───────────────────────────────┴─────────┘
│ data.creator_list[].researcher_id_list[].id_code │ 385,879 │ │ data.contributor_list[].researcher_id_list[].id_code │ 40 │fix: clean up PROCESS-DB after preprocessing completes
Previously, the PROCESS-DB Redis database retained DOI validation records between runs. When re-executing the processor, all DOIs were skipped as already processed, resulting in empty metadata output.
Changes:
- Rename cleanup_testing_storage to cleanup_storage and remove the testing-only condition so the database is always cleaned
- Optimize RedisDataSource.flushdb to use native Redis FLUSHDB
- Add test verifying consecutive runs produce identical output
Tutta la verità sugli UPDATE in Qlever
Section titled “Tutta la verità sugli UPDATE in Qlever”- Gli SPARQL UPDATE vengono salvati in un file separato chiamato <index_name>.update-triples. Questi dati non sono indicizzati come i dati principali.
- Ad ogni query, QLever deve combinare i dati dell’indice principale con i delta triples “al volo”. Questo causa rallentamenti.
- Stanno lavorando su un sistema di rebuild automatico in background, ma non è ancora pronto per la produzione.
- Ora c’è l’opzione qlever rebuild-index
- Combina indice originale + update-triples in un nuovo indice
- Crea l’indice in una sottocartella rebuild.YYYY-MM-DDTHH:MM
- Il nuovo indice ha tutte le triple già indicizzate (niente delta)
- Il vecchio indice (con il suo file update-triples) rimane intatto finché non lo cancelli manualmente

fix: preserve query parameters in endpoint URL and add QLever test backend [release]
Endpoint URLs with query parameters (e.g. ?default-graph-uri=...) were silently dropped when building request URLs. The fix parses the endpoint URL and merges existing parameters with the query/update parameter.
Integration tests now run against both Virtuoso and QLever via parametrized fixtures.
Please note that concrete syntaxes MAY support simple literals consisting of only a lexical form without any datatype IRI or language tag. Simple literals are syntactic sugar for abstract syntax literals with the datatype IRI
http://www.w3.org/2001/XMLSchema#string. (https://www.w3.org/TR/rdf11-concepts/#section-Graph-Literal)
fix: normalize RDF literals to xsd:string and tighten type annotations
Add sparql_binding_to_term and normalize_graph_literals for RDF 1.1 compliant literal handling.
Replace implicit None defaults with Optional,
test: replace Virtuoso with QLever and manage Docker via pytest fixtures
refactor(test): migrate from Virtuoso to QLever triplestore
Ho lanciato Meta e mi sono accorto che le query sono lentissime. Non perché Qlever sia lento, ma perché erano scritte in maniera ottimizzata per Virtuoso. In particolare per quanto riguarda il match di stringhe con e senza datatype. Per tagliare la testa al toro, voglio aggiungere il datatype esplicito a tutte le stringhe.
feat(patches): add script to add xsd:string datatype to untyped literals
Uses RDFLib Dataset for named graph support, parallel processing with ProcessPoolExecutor, and Rich for progress display.
Found 2604349 ZIP files to process Processing files ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2604349/2604349 14:21:08 0:00:00
Statistics: Files processed: 2604349 Files modified: 2042735 Files unchanged: 561614
Modifications by property: http://purl.org/dc/terms/description: 1338496617 http://xmlns.com/foaf/0.1/familyName: 300471275 http://xmlns.com/foaf/0.1/givenName: 298492984 http://www.essepuntato.it/2010/06/literalreification/hasLiteralValue: 223214384 http://purl.org/dc/terms/title: 110828015 http://prismstandard.org/namespaces/basic/2.0/endingPage: 74981713 http://prismstandard.org/namespaces/basic/2.0/startingPage: 74981712 https://w3id.org/oc/ontology/hasUpdateQuery: 74525198 http://xmlns.com/foaf/0.1/name: 41588595 http://purl.org/spar/fabio/hasSequenceIdentifier: 8326449 http://prismstandard.org/namespaces/basic/2.0/publicationDate: 687301
Total literals modified: 2546594243feat(patches): add script to fix publication date datatypes
Scanning /mnt/arcangelo/oc_meta_dev/rdf_datatyped for ZIP files...Found 2604349 ZIP files to process Processing files ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2604349/2604349 0:26:29 0:00:00
Statistics: Files processed: 2604349 Files modified: 5271 Files unchanged: 2599078
Modifications by datatype: http://www.w3.org/2001/XMLSchema#gYear: 336915 http://www.w3.org/2001/XMLSchema#gYearMonth: 320342 http://www.w3.org/2001/XMLSchema#date: 30044
Total dates fixed: 687301refactor(patches): unify datatype fix scripts into single module
Applicare questo fix ha portato a un decremento del numero di triple da 13,556,089,823 a 13,556,086,129, ovvero 3,694 triple in meno. Questo si spiega con l’eliminazione dei duplicati. È possibile che per una stessa entità la stessa tripla fosse presente prima senza il datatype e poi con il datatype.
Trovato
{ "@id": "https://w3id.org/oc/meta/br/06704211544", "@type": [ "http://purl.org/spar/fabio/Expression", "http://purl.org/spar/fabio/JournalArticle" ], "http://prismstandard.org/namespaces/basic/2.0/publicationDate": [ { "@type": "http://www.w3.org/2001/XMLSchema#gYear", "@value": "2017" }, { "@value": "2017" } ]}https://w3id.org/oc/meta/br/06704211544.json
L’indice testuale di QLever viene usato per il match esatto di stringa?
Section titled “L’indice testuale di QLever viene usato per il match esatto di stringa?”No. L’indice testuale viene attivato solo quando la query SPARQL usa esplicitamente
i predicati ql:contains-word o ql:contains-entity. Un match esatto di stringa
(ad esempio FILTER(?x = "valore") oppure un letterale in un triple pattern) segue
un percorso di esecuzione completamente diverso, che usa le permutazioni standard
del knowledge graph (SPO, PSO, ecc.) senza mai toccare l’indice testuale.
meta_prov_fixer
Section titled “meta_prov_fixer”Non mi ricordavo se avessi applicato o meno le correzioni di provenance di Elia alla cartella RDF su cui stavo lavorando. per cui ho sentito la necessità di lanciare una dry run dello strumento di Elia per verificare se ci fossero problemi di conformità. Tuttavia, ho riscontrato l’assenza di una modalità di dry run efficiente e quindi ho chiesto a Elia il permesso di crearne una.
build: migrate from Poetry to UV, add CI workflow and ISC license
Peffomance
Section titled “Peffomance”OpenCitations è Python rdflibound
Section titled “OpenCitations è Python rdflibound”- Contare quante triple ci sono nei file rdf in parallelo con 16 core utilizzando rdflib impiega 3 giorni. Utilizzando parsing json impiega 20 minuti.
- https://github.com/oxigraph/oxigraph/discussions/1092
I colli di bottiglia principali
Section titled “I colli di bottiglia principali”1. Creazione degli oggetti Term (URIRef, Literal, BNode)
Section titled “1. Creazione degli oggetti Term (URIRef, Literal, BNode)”Ogni singolo termine RDF parsato diventa un oggetto Python con validazione completa:
- URIRef: ogni creazione chiama
_is_valid_uri()che controlla 11 caratteri invalidi, piùurljoin()se c’è una base URI - Literal: valida il language tag con regex, crea un nuovo
URIRef(datatype)per il datatype (che a sua volta rivalida l’URI), esegue casting lessicale-Python, controlla well-formedness, valida Unicode - BNode: lasciamo perdere
- Nessun caching: termini identici vengono ricreati da zero ogni volta. Un dataset con 1M di triple crea ~3M di oggetti term, ognuno con tutta la validazione
2. Store in memoria
Section titled “2. Store in memoria”Il Memory store mantiene 5 strutture dati per ogni tripla:
- 3 indici dizionario (
__spo,__pos,__osp) __tripleContexts: mapping tripla -> contesto__contextTriples: mapping contesto -> set di triple
Il metodo triples() wrappa ogni .keys() con list(), creando copie complete ad ogni iterazione
3. Parser: nessun batching
Section titled “3. Parser: nessun batching”Tutti i parser aggiungono triple una alla volta con Graph.add(). Ogni chiamata:
- Spacchetta la tripla per validare i tipi con
assert isinstance() - Rimpacchetta in una nuova tupla
- Chiama
store.add()che indicizza in 3 dizionari + gestisce il contesto
Il buffer di lettura di NTriples è hardcoded a 2048 byte. I file moderni beneficerebbero di 64KB+. Il parser JSON-LD carica l’intero documento in memoria prima di processarlo
4. SPARQL: nessuna ottimizzazione del piano di query
Section titled “4. SPARQL: nessuna ottimizzazione del piano di query”E se facessi un fork? E se usassi pyoxigraph?
Section titled “E se facessi un fork? E se usassi pyoxigraph?”Contare le triple con pyoxigraph produce lo stesso risultato che contarle parsando il json e ci mette ~50 minuti vs ~15 minuti. rdflib ci mette più di due giorni.
arcangelo@serverGrosso:/mnt/arcangelo/repositories/oc_meta$ uv run python '/mnt/arcangelo/repositories/oc_meta/oc_meta/run/count/triples.py' /mnt/arcangelo/fixed/ --pattern *.zip --format json-ld --recursive --workers 16 --fast Counting triples ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 1302184/1302184 0:15:56 0:00:00Total triples: 8451129250arcangelo@serverGrosso:/mnt/arcangelo/repositories/oc_meta$ uv run python '/mnt/arcangelo/repositories/oc_meta/oc_meta/run/count/triples.py' /mnt/arcangelo/fixed/ --pattern *.zip --format json-ld --recursive --workers 16 --backend pyoxigraph Counting triples ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 1302184/1302184 0:47:13 0:00:00Total triples: 8451129250Convertire gli RDF con pyoxigraph e 29 processi impiega 21 minuti, con rdflib 1 ora e 17.
Esplorazione cartelle
Section titled “Esplorazione cartelle”os.walk: 152.128s sull’RDF di Meta os.scandir BFS: 33.203s parallel BFS: 378.310s scandir-rs: 12.909s
Parsing json
Section titled “Parsing json”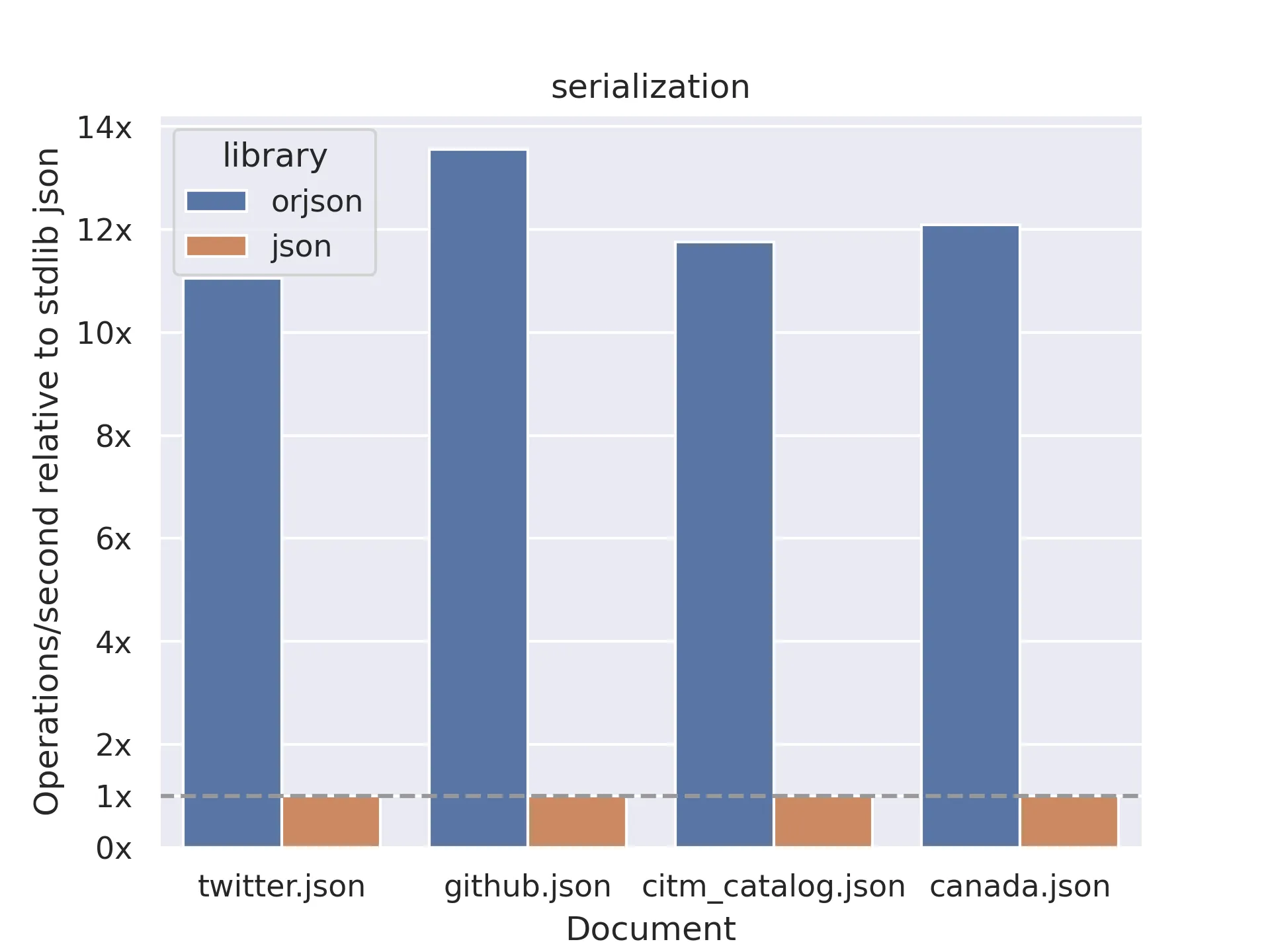
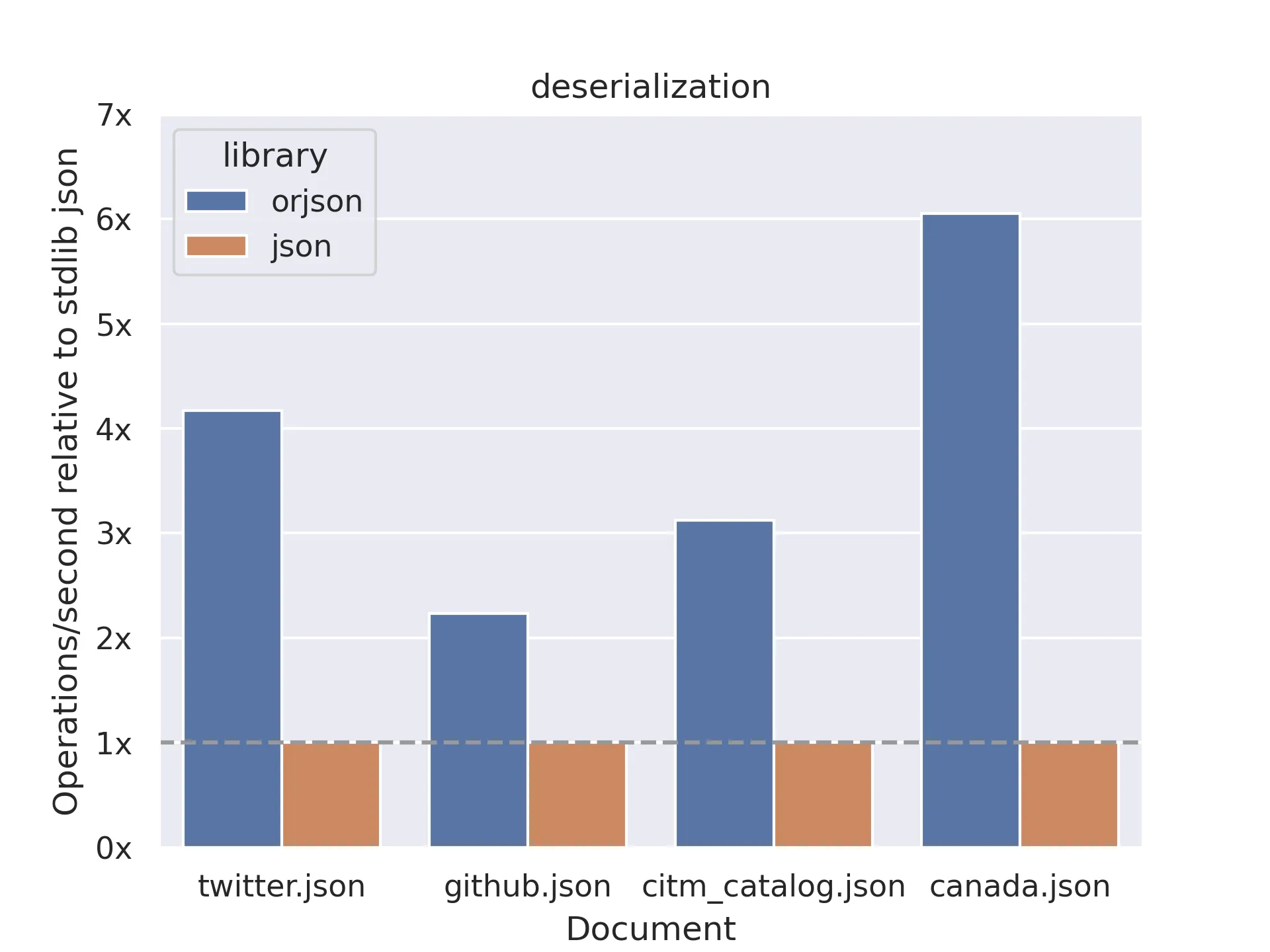
Domande
Section titled “Domande”- Ho introdotto il meccanismo di integrazione tra DOI ORCID INDEX e sorgente, nonché il meccanismo di normalizzazione dei nomi dei publisher, basato solo sul prefisso e non sul member, anche per JALC dove non erano presenti. Ha senso?
- contributor_list per JALC non viene usato, solo creator_list. Ci piace?
- Gli studenti mi hanno chiesto un quinto laboratorio, ma mi sono accorto che il prossimo slot disponibile è l’8 aprile, cioè tra 3 settimane. Come mai? Io avevo intenzione di farlo tra 2 settimane, tra 3 mi sembra eccessivo.
- I risultati del workshop?