2025-11-25 Meta carica in bulk su Virtuoso
La Novitade
Section titled “La Novitade”- Dopo aver imposto un limite e un’allocazione alla RAM per ciascun container utilizzato dal processo di Meta le performance sono diventate ragionevoli, segno che il problema era un problema di swap.
- Tuttavia, le performance rimangono distanti da quelle che ottengo in fase di benchmark. Una possibilità è che la complessità scali in maniera quadratica con la dimensione. Infatti, sto utilizzando in produzione 3000 righe per file anziché 1000 righe per file come nei benchmark. Un’altra possibilità è che il problema sia la dimensione del database di partenza.
- Per testare queste possibilità ho esteso il benchmark per ripetere i risultati più di una volta, sia con dei dati nuovi a ogni run, sia con gli stessi dati. Questo mi permette di calcolare statistiche come media, mediana, outlier, deviazione standard, intervallo di confidenza.
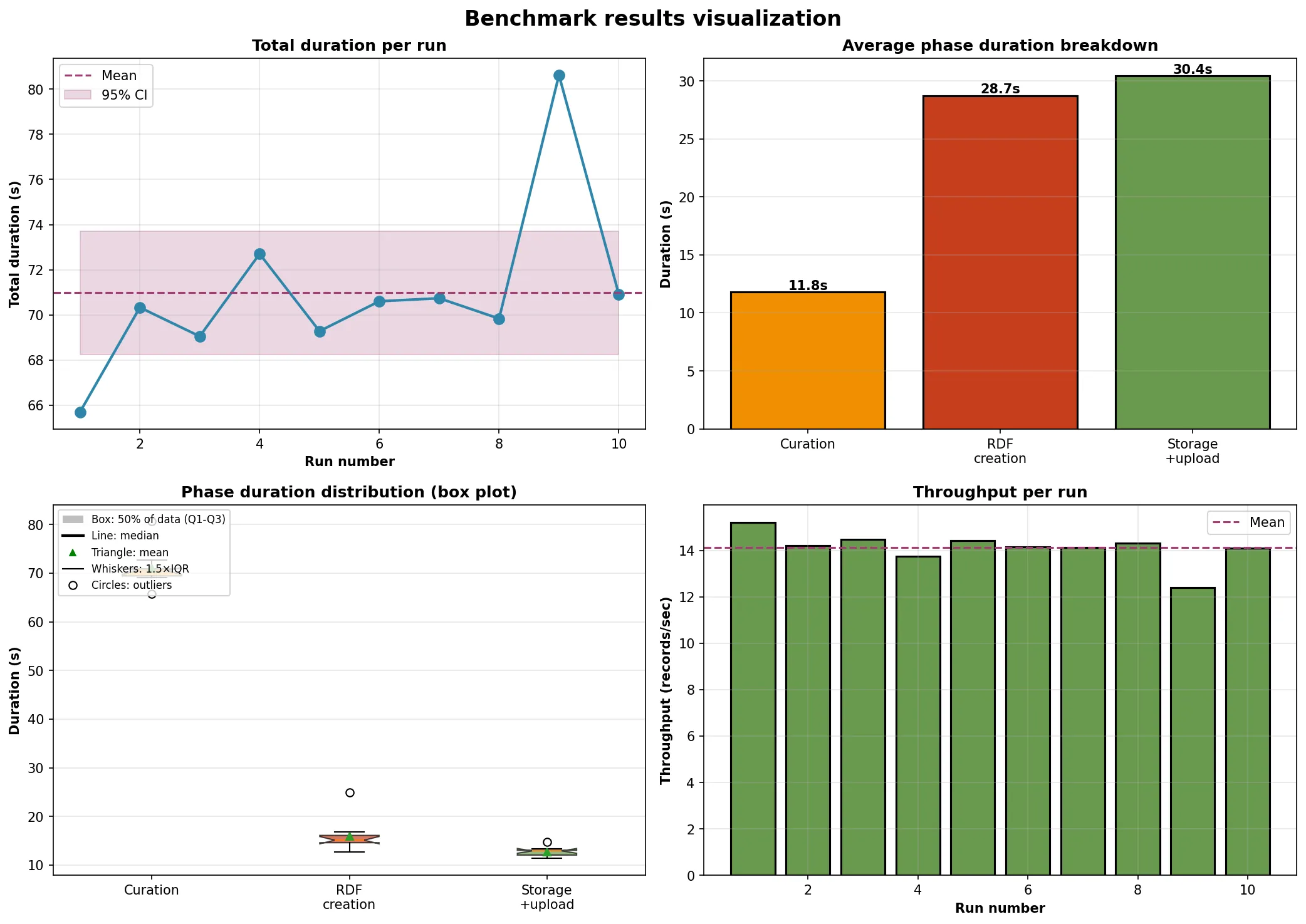
- Ecco i risultati di partenza con 10 run su dati nuovi ogni volta ma stesso numero di righe (1000):
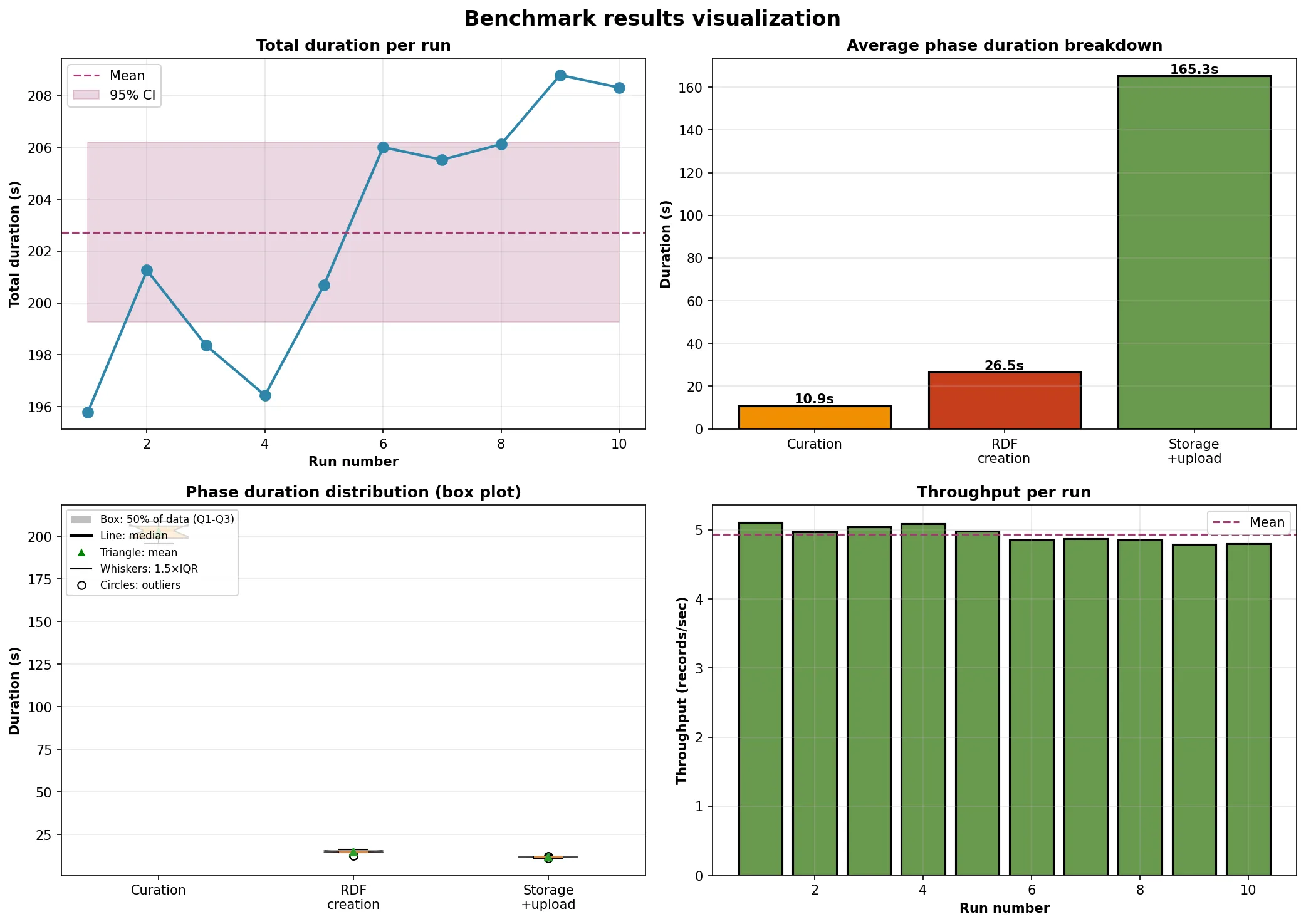
- Ho spostato la funzione di timing dal benchmark al processo di Meta, aggiungendo due nuovi parametri
timingetiming-output, riutilizzando poi le metriche generate dal processo vero e proprio in fase di benchmark. Semplicemente lo script di benchmark a questo punto diventa un orchestratore.poetry run python3 -m oc_meta.run.meta_process -c /mnt/arcangelo/oc_meta_merge/meta_config.yaml --timing --timing-output ./meta_process_timing.json - Ho riscontrato numerose inefficienze legate alla generazione dei file contenenti le query SPARQL. Innanzitutto io avevo predisposto un sistema che in fase di salvataggio dei file RDF andava a controllare prima se ciascuna entità fosse stata modificata. Noi sappiamo che un’entità è stata modificata perché durante la generazione della provenance ci salviamo in un set l’insieme delle entità modificate. Tuttavia, questo set non veniva utilizzato dalla funzione che genera i file SPARQL. Inoltre, veniva computata la differenza tra grafi isomorfi e eventualmente cercato un grafo preesistente anche per le entità di provenance che non hanno mai bisogno di queste informazioni.
- Bulk loading Virtuoso. Gli INSERT divenvano nquads zippati e vengono eseguiti tramite bulk load dopo i DELETE, che invece vengono eseguiti tramite query SPARQL.
virtuoso_bulk_load:enabled: Truedata_container: oc-meta-test-virtuosoprov_container: oc-meta-test-virtuoso-provbulk_load_dir: /database/bulk_loaddata_mount_dir: test/test_virtuoso_db/bulk_loadprov_mount_dir: test/test_virtuoso_db_prov/bulk_load
oc_ocdm
Section titled “oc_ocdm”Altri miglioramenti di performance
# Prima O(n^2)def get_br(self) -> Tuple[BibliographicResource]: result: Tuple[BibliographicResource] = tuple() for ref in self.res_to_entity: entity: GraphEntity = self.res_to_entity[ref] if isinstance(entity, BibliographicResource): result += (entity, )return result
# Dopo O(n)def get_br(self) -> Tuple[BibliographicResource]: return tuple(entity for entity in self.res_to_entity.values() if isinstance(entity, BibliographicResource))# Prima, lista intermedia inutilefor g in self.a_set.graphs(): cg.addN([item + (g.identifier,) for item in list(g)])
# Dopofor g in self.a_set.graphs(): cg.addN(item + (g.identifier,) for item in g)- Mi salvo le directory già create anziché fare os.makedirs(cur_dir_path, exist_ok=True) ogni volta che comunque deve fare I/O.
- Modifiche alla funzione upload_all()
Sono stati aggiunti 4 nuovi parametri opzionali:
- separate_inserts_deletes: se True, gestisce INSERT e DELETE separatamente
- save_inserts_as_nquads: se True, salva le INSERT come file .nq.gz compressi
- nquads_output_dir: directory di output per i file N-Quads (obbligatoria se save_inserts_as_nquads=True)
- nquads_batch_size: numero di quad per file (default: 1.000.000)
Virtuoso utilities
Section titled “Virtuoso utilities”- Lo script imposta sia limit che reservation sul container. Se l’utente specifica —memory, l’85% viene usato per Virtuoso, modificando il file .ini e viene riservato, mentre il 100% corrisponde al limit utilizzabile dal container.
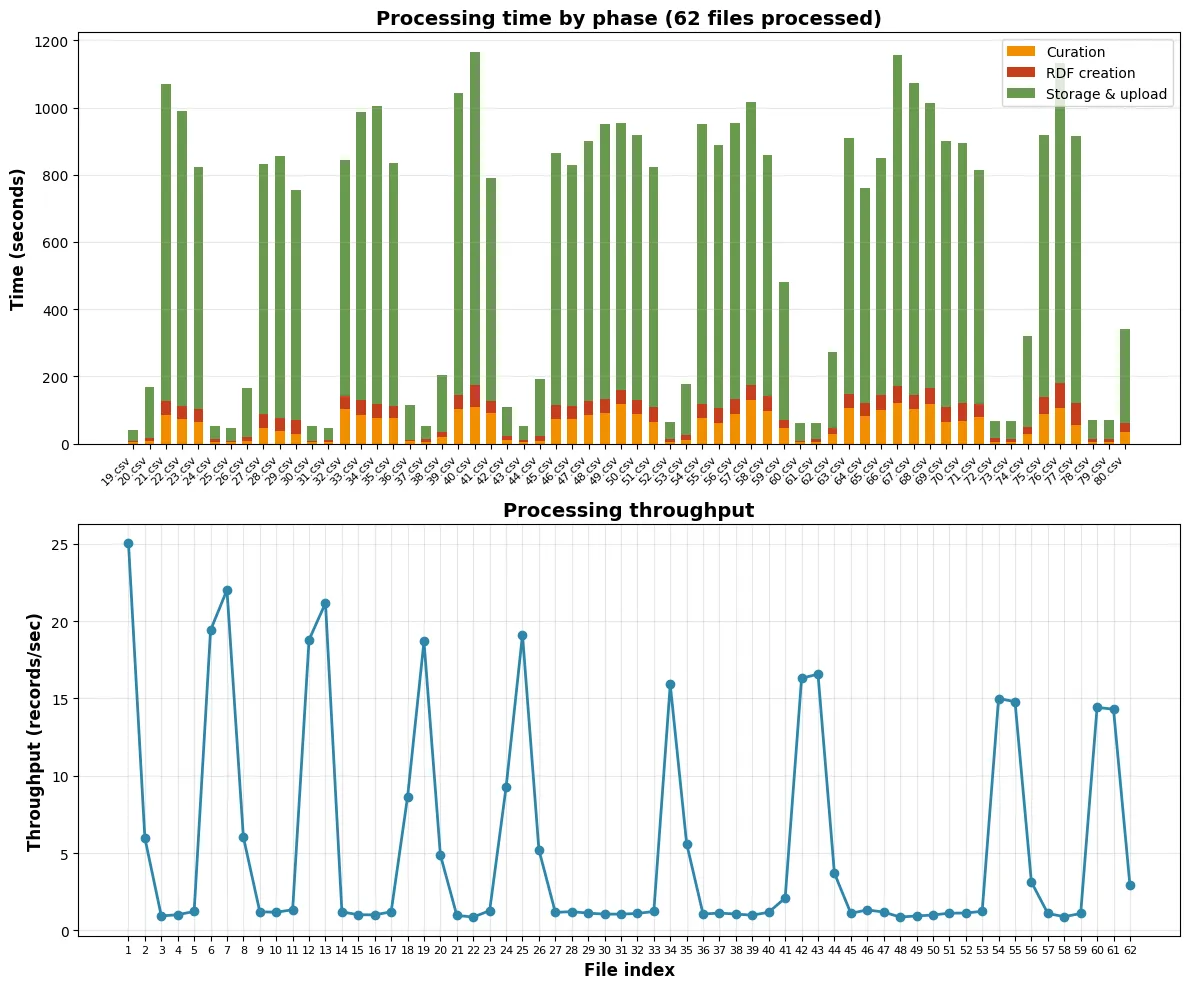
- Dopo aver impostato limit e reservation per Redis e ridotto la dimensione dei file di input, 1 file viene processato in 11 minuti, che è compatibile con i risultati benchmark. In questo modo, il tempo previsto per processare tutti i file, ovvero 3,7 milioni di entità, è 233 ore, cioè 10 giorni in single process. Male ma non malissimo.
- Ho migliorato lo script di bulk loading per essere importabile come modulo oltre che lanciabile da linea di comando e ho aggiunto dei test di integrazione con workflow di esecuzione automatica su GitHub.