2025-12-09 minmax
La Novitade
Section titled “La Novitade”oc_meta
Section titled “oc_meta”Arrivato pressoché alla fine dell’ingestione di Crossref, il database dei dati è diventato inutilizzabile e ha smesso di ricevere sia query di lettura che di scrittura. Nei log ho trovato un’infinità di log, gigabyte e gigabyte di log, che segnalavano un’inconsistenza nella paginazione. L’unica spiegazione che riesco a dare è che eseguire bulk load troppo frequenti spacchi il database.
Si ricomincia d’accapo, senza bulk load.
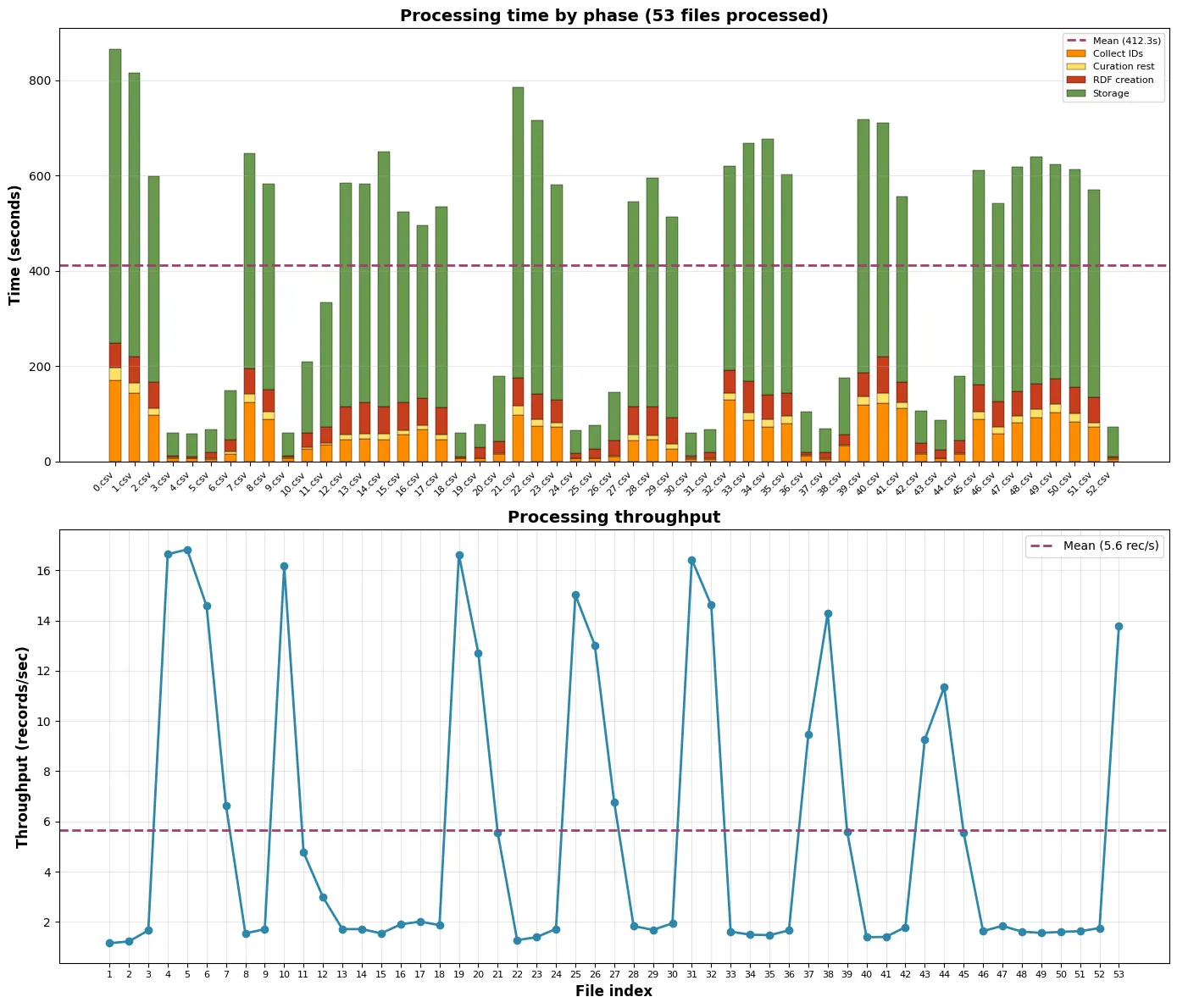

refactor: migrate from SPARQLWrapper to sparqlite
oc_ocdm
Section titled “oc_ocdm”https://pytest-benchmark.readthedocs.io/en/latest/
feat: add benchmark infrastructure
Add pytest-benchmark configuration and benchmarks for testing provenance generation, reading e writing operations.
class MockEntity: def __init__(self, current_graph, preexisting_graph): self.g = current_graph self.preexisting_graph = preexisting_graph self.to_be_deleted = False
class TestGraphDiff: @pytest.mark.benchmark(group="graph_diff") @pytest.mark.parametrize("entity_count", [50, 100, 150]) def test_compute_graph_changes_modified( self, benchmark, redis_counter_handler, entity_count ): def setup(): graph_set, brs = create_populated_graph_set( redis_counter_handler, entity_count ) entities = [] for entity in graph_set.res_to_entity.values(): preexisting = Graph() for triple in entity.g: preexisting.add(triple) mock = MockEntity(entity.g, preexisting) entities.append(mock) for i, br in enumerate(brs): br.has_title(f"Modified Title {i}") return (entities,), {}
def compute_changes(entities): results = [] for entity in entities: result = _compute_graph_changes(entity, "graph") results.append(result) return results
result = benchmark.pedantic( compute_changes, setup=setup, rounds=BENCHMARK_ROUNDS ) assert len(result) >= entity_count * 14 entities_with_changes = sum( 1 for to_insert, to_delete, n_added, n_removed in result if n_added > 0 or n_removed > 0 ) assert entities_with_changes == entity_count, ( f"Expected {entity_count} entities with changes, " f"got {entities_with_changes}" )Esegue il test e genera automaticamente statistiche.
Diff con grafi isomorfi: 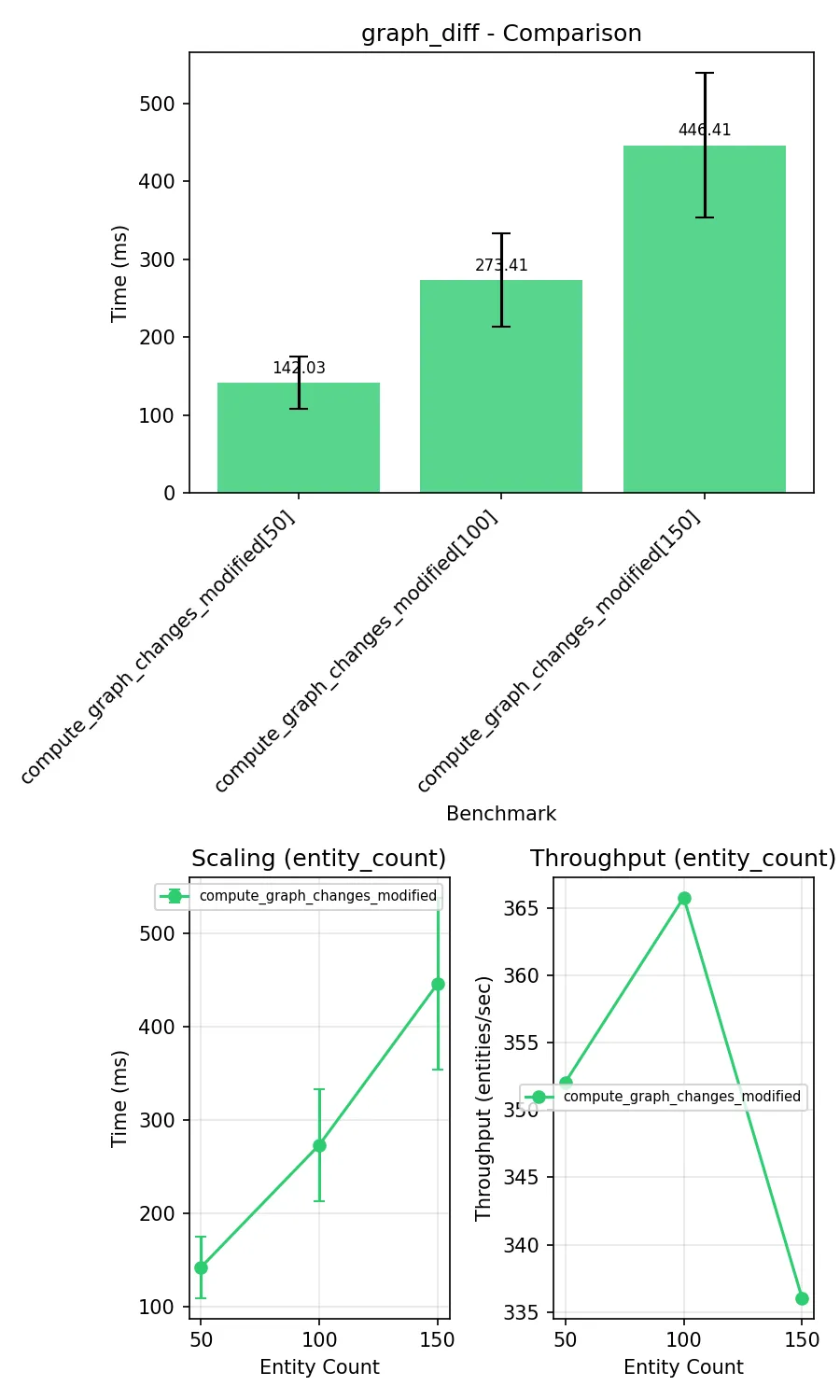
Diff tra set: 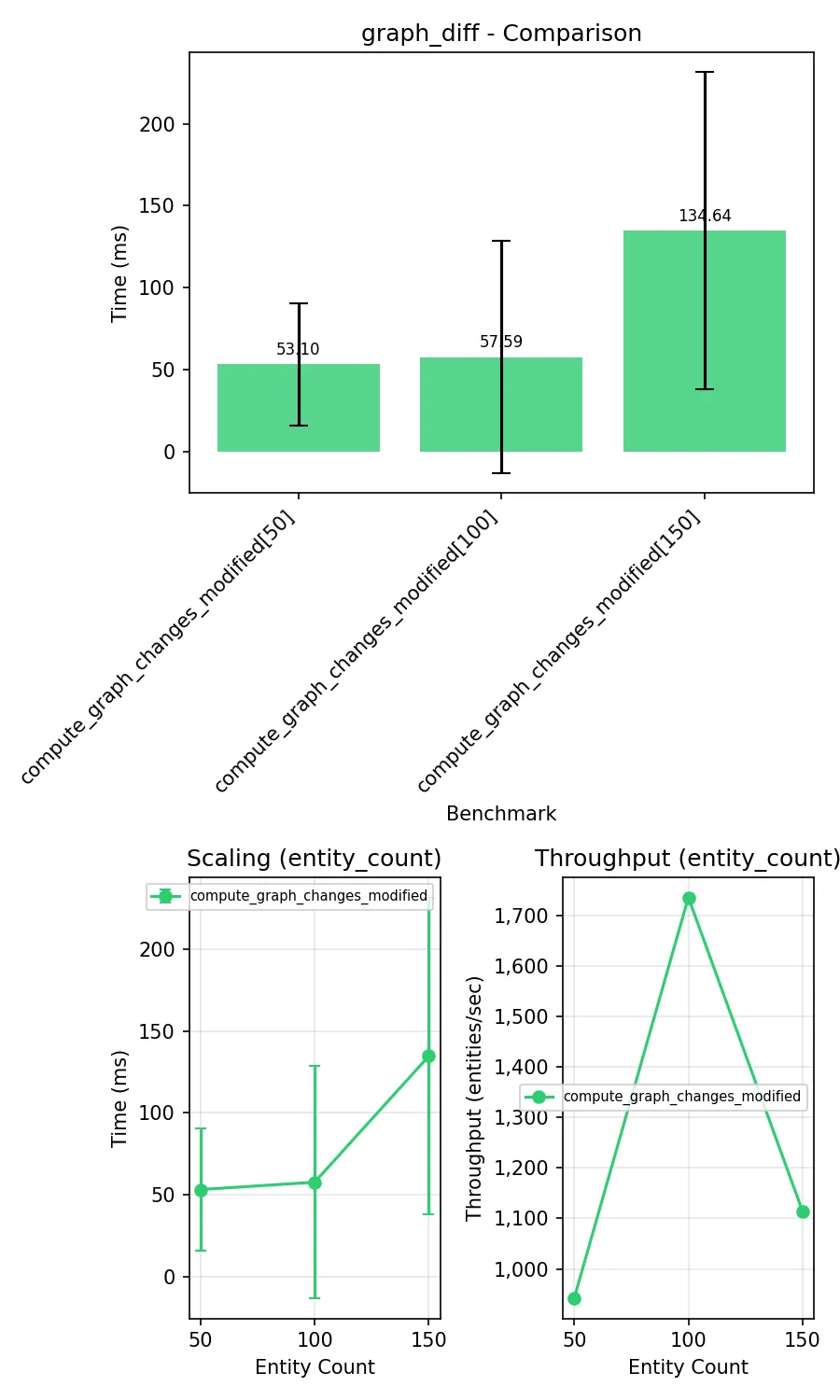
fix(query_utils): replace isomorphic graph comparison with set operations [release]
Use simple set difference instead of to_isomorphic() and graph_diff() for detecting changes between graphs. This is valid because OCDM never uses blank nodes (all resources have URIs).
fix(query_utils): replace Graph objects with sets in _compute_graph_changes
Eliminate unnecessary Graph object creation when computing triple differences. The previous implementation created Graph objects and added triples in a loop, which was slow. Since callers only iterate over the results, sets work equally well and provide ~10x speedup in benchmarks.
fix(storer): remove unnecessary Dataset reconstruction in _store_in_file
The hack was originally needed with ConjunctiveGraph (rdflib < 7) to ensure provenance triples were written correctly. After migration to Dataset with quads() in rdflib 7.4.0, this reconstruction became a redundant copy operation.
Also adds storer benchmark for measuring file I/O performance.
Prima: 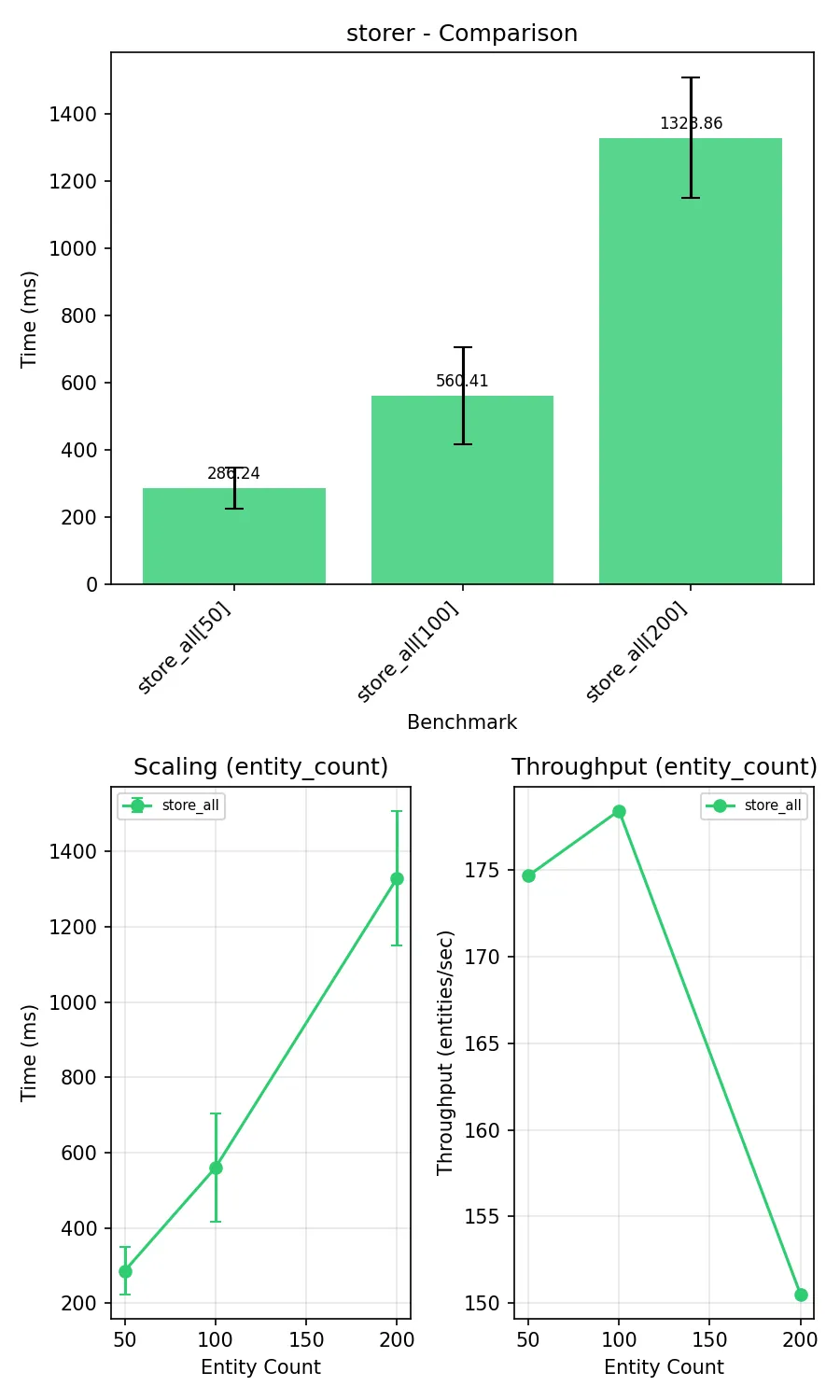
Dopo: 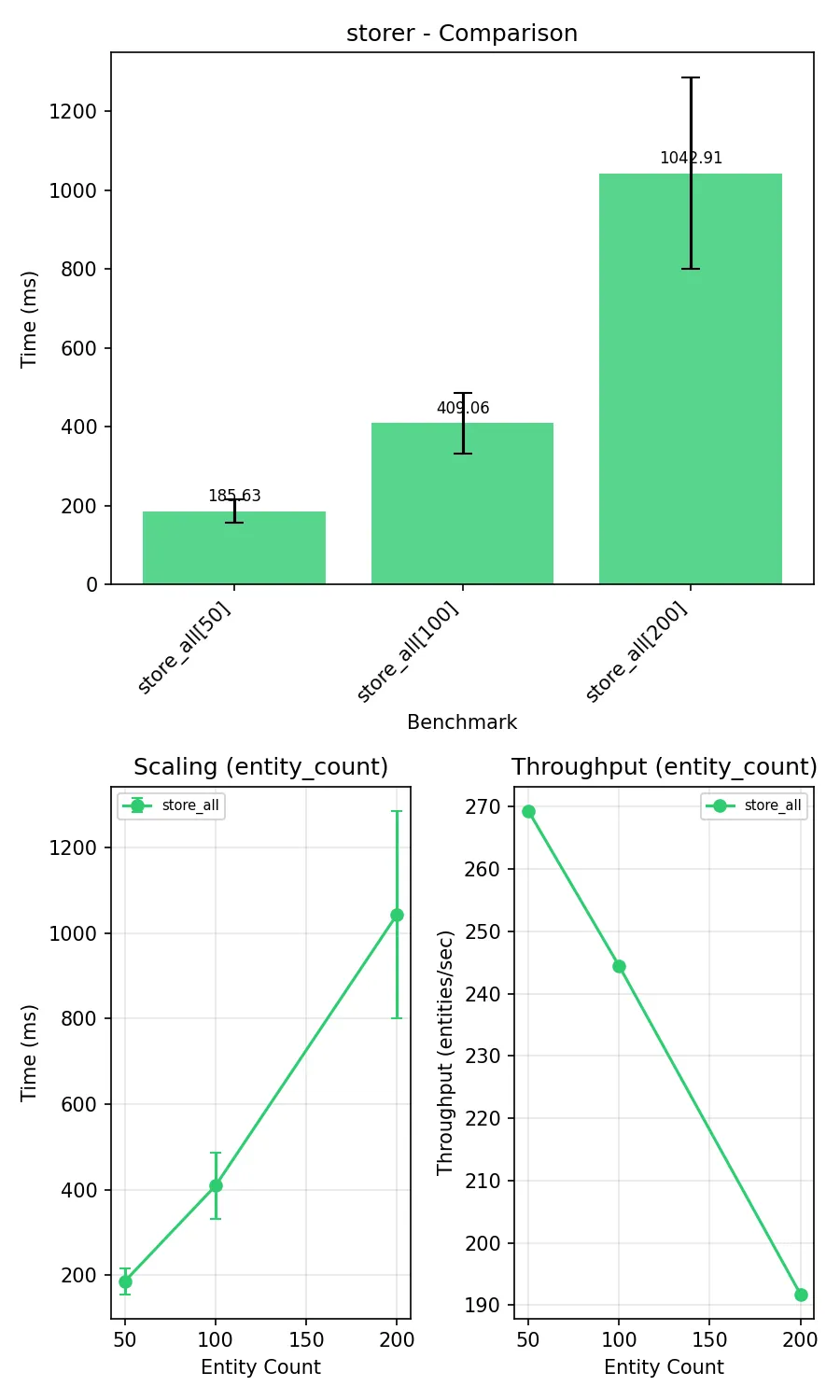
fix(support): optimize find_paths with single regex match
Add parse_uri() function that extracts all URI components in one regex match instead of calling get_short_name(), get_prefix(), get_count() separately. Remove unused get_prov_subject_* functions.
Prima: 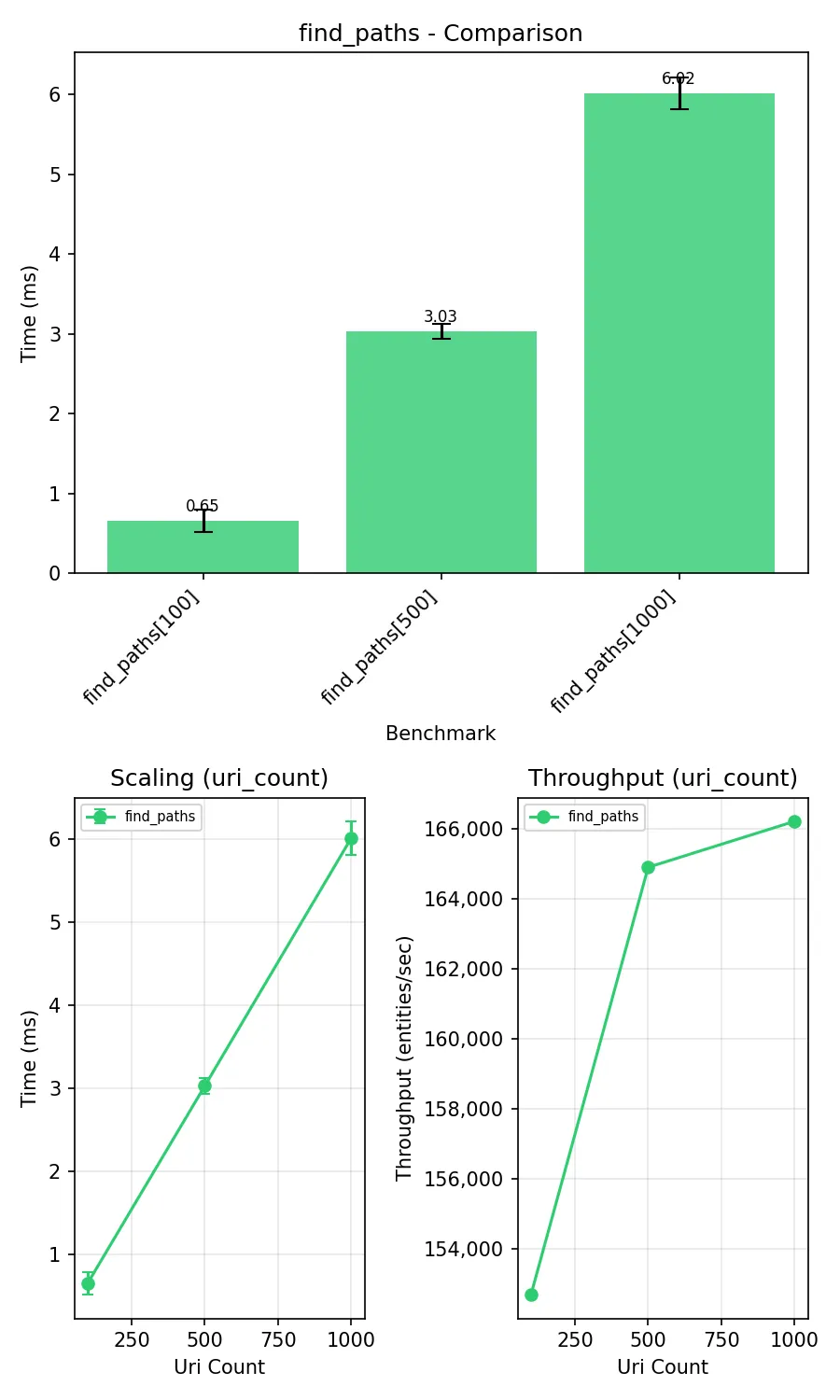
Dopo: 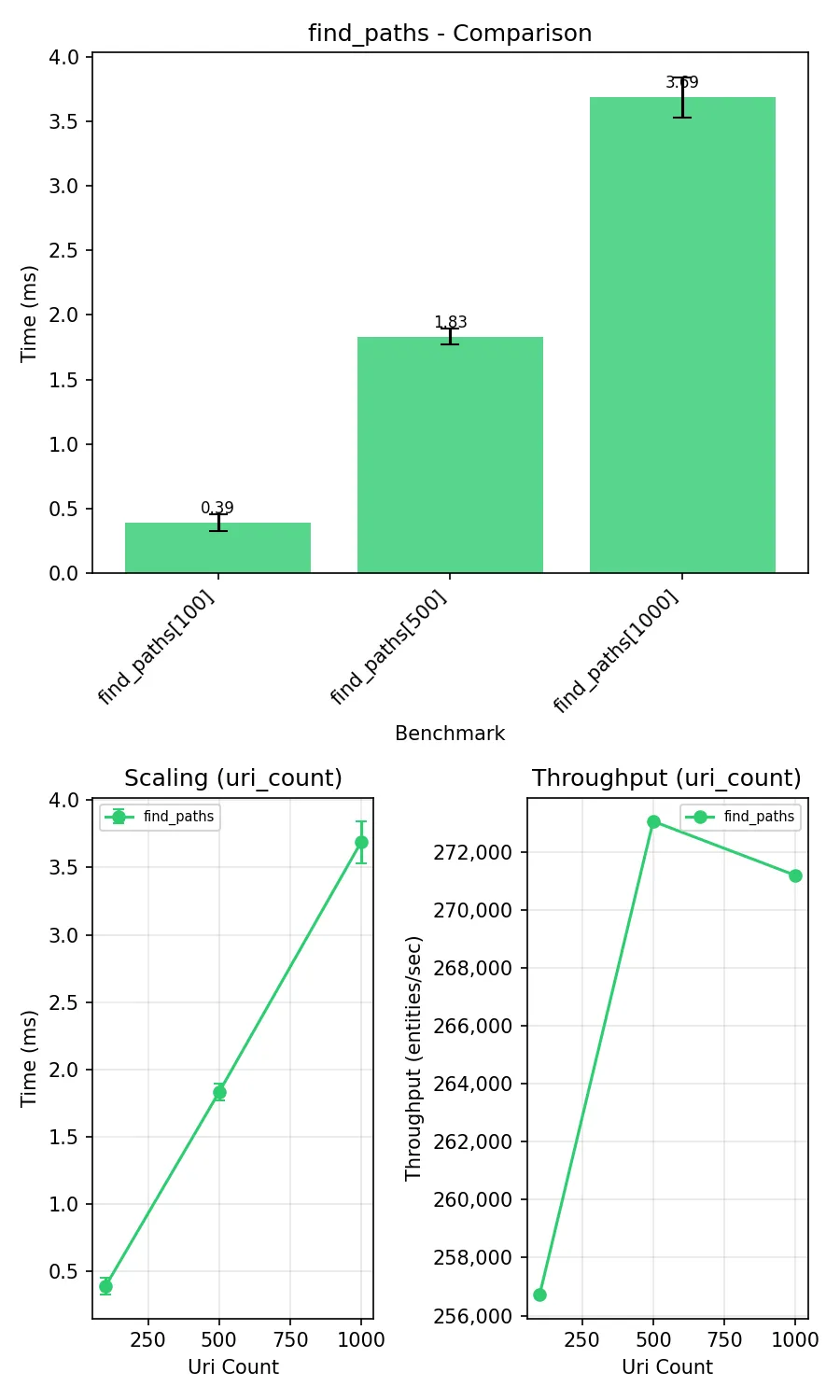
perf(support): cache parse_uri results and refactor URI helper functions
Add LRU cache to parse_uri() and refactor get_short_name(), get_count(), get_prefix(), get_base_iri(), get_resource_number() to use cached parse_uri() instead of _get_match() which compiled regex on every call.
Benchmark improvement: ~1.6x speedup on find_paths operations.
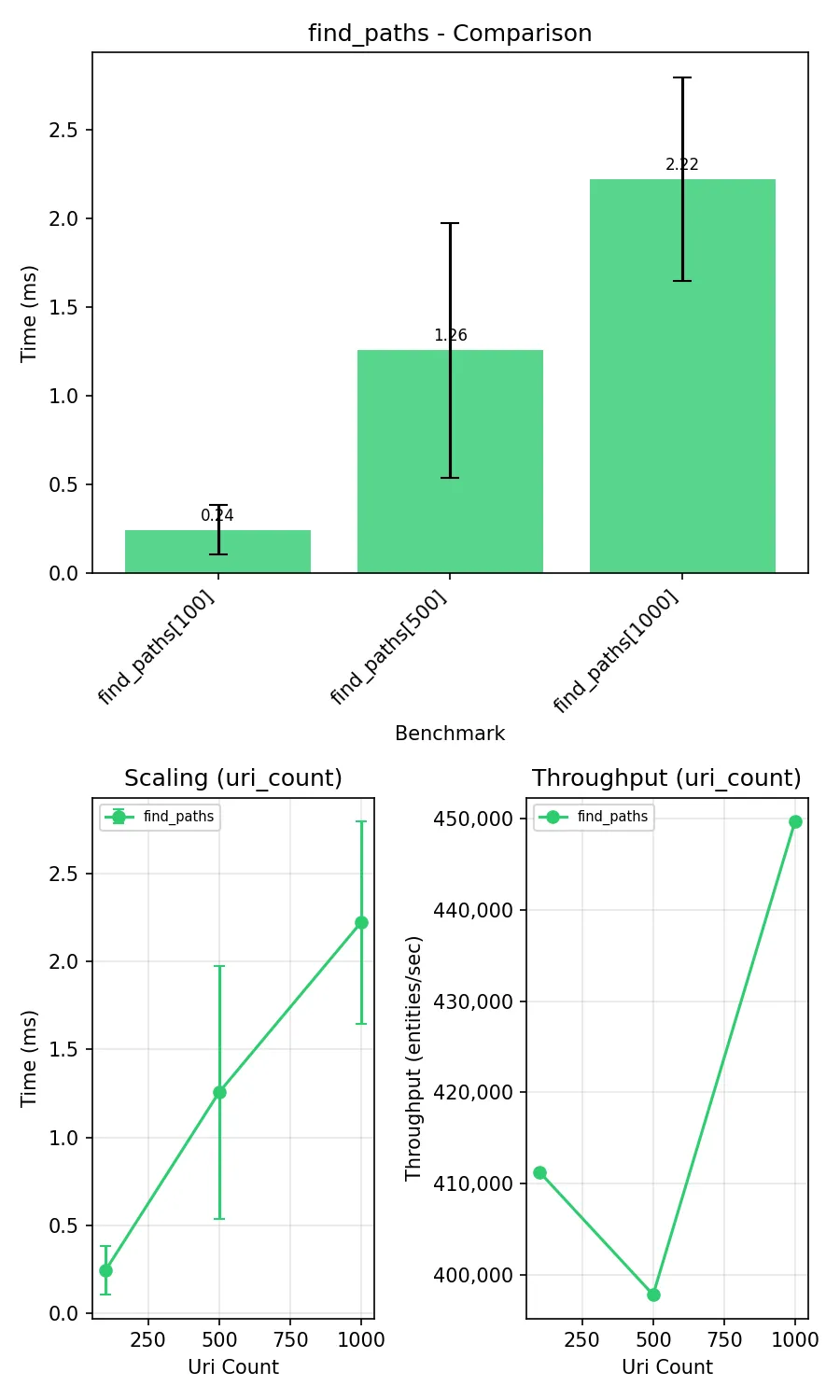
fix(sparql): migrate from SPARQLWrapper to sparqlite
[release]
fix(sparql): add query chunking to prevent oversized SPARQL requests
Queries with more than 500 triples are now split into multiple chunks. The batching mechanism combines these chunks up to batch_size per request.
[release]
Questa logica prima era in oc_meta, ma richiedeva il parsing della query. L’ho spostata in oc_ocdm. Un chunk è o un’entità o un gruppo di triple pattern fino a 500 (perché Virtuoso accetta di default massimo 1000 per query).
Ho spostato il database di provenance su un altro disco per ridurre la competizione sull’I/O.
Repository setup guides
Section titled “Repository setup guides”shacl-extractor
Section titled “shacl-extractor”
fix: generate per-module SHACL shapes with separate namespaces
- Generate shapes in module-specific namespaces (e.g., skg_sh_agent:, skg_sh_grant:)
- Add sh:targetClass only for root classes of each module
- Use sh:node for nested entity validation instead of sh:class
- Drop support for single-file ontologies (version < 1.0.1)
sparqlite
Section titled “sparqlite”
test: add benchmark suite for SPARQL client comparison
Compares sparqlite, SPARQLWrapper, and rdflib against a Virtuoso endpoint. Includes analytics for generating performance reports.
docs: add benchmarks page comparing sparqlite vs rdflib and SPARQLWrapper
Add documentation describing benchmark methodology and results. Sparqlite shows significant performance advantages: 3-4x on CONSTRUCT, 2-2.5x on ASK, ~2x on UPDATE, and 1.4-1.8x on SELECT queries.
https://opencitations.github.io/sparqlite/architecture/benchmarks/
virtuoso_utilities
Section titled “virtuoso_utilities”Each buffer caches one 8K page of data and occupies approximately 8700 bytes of memory (https://docs.openlinksw.com/virtuoso/ch-server/)
Io stavo calcolando il numero di buffer facendo (memory × 0.85 × 0.66) / 8000, dev’essere (memory × 0.85 × 0.66) / 8700.
AsyncQueueMaxThreads: control the size of a pool of extra threads that can be used for query parallelization. This should be set to either 1.5 * the number of cores or 1.5 * the number of core threads; see which works better (https://github.com/dbcls/bh11/wiki/Virtuoso-configuration-tips)
“For a number of reasons, the rdf:type predicate (often expressed as a, thanks to SPARQL/Turtle semantic sugar) can be a performance killer. Removing those predicates from your graph pattern is likely to boost performance substantially. If needed, there are other ways to limit the solution set (such as by testing for attributes only possessed by entities your desired rdf:type) which do not have such negative performance impacts.” (https://stackoverflow.com/questions/39748060/complex-sparql-query-virtuoso-performance-hints)
feat(launch_virtuoso): add query parallelization and memory optimization
Add --parallel-threads option to configure CPU-based threading parameters. Automatically calculate AsyncQueueMaxThreads, ThreadsPerQuery, MaxClientConnections, and ServerThreads based on available CPU cores. Add MaxQueryMem calculation to prevent OOM errors during query execution. Enable adaptive vector sizing for better performance on large queries. Correct buffer size calculation from 8000 to 8700 bytes per buffer.
[release]
feat(native_entrypoint): add docker-compose compatible entrypoint
Add virtuoso-native-launch command that configures Virtuoso from environment variables and delegates to the original Docker entrypoint. This enables using optimized Virtuoso configuration in docker-compose scenarios.
Add documentation and unit tests
services: virtuoso: build: context: . dockerfile: Dockerfile.virtuoso environment: - VIRTUOSO_ENABLE_WRITE_PERMISSIONS=true volumes: - ./virtuoso-data:/opt/virtuoso-opensource/database ports: - "8890:8890" - "1111:1111"FROM openlink/virtuoso-opensource-7:latest
RUN pip install virtuoso-utilities
ENTRYPOINT ["virtuoso-native-launch"]feat(benchmarks): add parallel SPARQL query benchmarks
Add pytest-benchmark tests measuring query performance at different parallelism levels (1, 25%, 50%, 75%, 100% of CPU cores) for SPO, DOI lookup, VVI, and mixed workloads.
Includes documentation page.
https://opencitations.github.io/virtuoso_utilities/benchmarks/
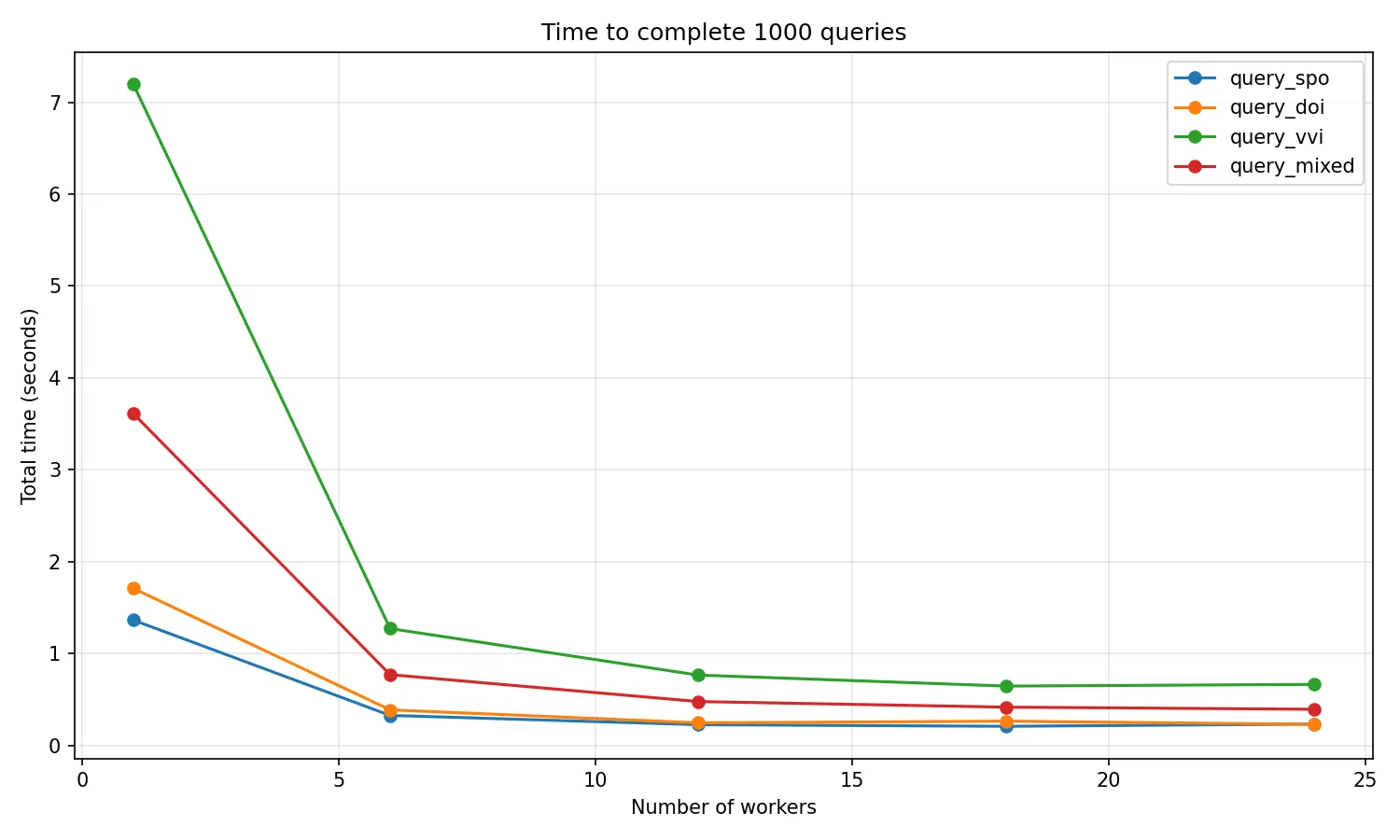
È assurdo che le stesse query fatte sullo stesso database, in benchmark, sul mio PC, funzioni tutto perfettamente, in produzione, la stessa versione di Virtuoso, dia Monitor: Locks are held for a long time.
Ho provato ad eseguire lo stesso benchmark anche sul database di produzione e anche lì non dà problemi. Segno che il problema sul parallelismo potrebbe non essere di Virtuoso ma del mio codice. Solo che non capisco dove perché le query che sto facendo nel benchmark sono identiche per forma e per dimensionalità a quelle che faccio per Meta, e anche sullo stesso database
python-package-template
Section titled “python-package-template”
feat: initial Python package template
Template for Python packages with:
- Interactive setup.py script for project configuration
- GitHub Actions workflows (tests, release, docs deployment)
- UV-based dependency management with pyproject.toml
- Semantic-release configuration for automated versioning
- Optional Starlight documentation (generated dynamically via npm)
- ISC license
Run python setup.py after creating a repository from this template.
docs: add Python package template guide
Add getting started guide for the template repository with:
- Quick start section (5 steps to create a new package)
- Under the hood section explaining workflows and configuration
- Links to related guides for deeper understanding
Update homepage and sidebar to feature the template prominently.
https://opencitations.github.io/repository_setup_guides/
Aldrovandi
Section titled “Aldrovandi”
feat: add SharePoint folder structure extractor with cookie-based authentication
Obiettivo
Section titled “Obiettivo”Per ogni oggetto digitalizzato (263 totali in 6 Sale), generare meta.ttl e prov.nq nelle 4 sottocartelle (raw, rawp, dcho, dchoo) con i metadati specifici per ogni fase.
Mappatura step KG -> sottocartelle
Section titled “Mappatura step KG -> sottocartelle”| Sottocartella | Step KG | Contenuto | Software |
|---|---|---|---|
raw/ | 00 | Foto grezze acquisizione | Fotocamera |
rawp/ | 01 | Ricostruzione 3D | 3DF Zephyr |
dcho/ | 02-04 | Modello 3D completo | Blender, GIMP, Instant Meshes |
dchoo/ | 05-06 | Modello ottimizzato e pubblicato | CHAD-AP, Aton, Nextcloud |
| In realtà, nel kg, per ogni oggetto (es. la Carta Nautica, NR=1) ci sono due tipi di informazioni: |
- Il processo di DIGITALIZZAZIONE (step 00-06)
Queste triple descrivono come e’ stato creato il modello 3D:
act/1/00/1 = “Federica Bonifazi ha fotografato l’oggetto con Nikon D7200” act/1/01/1 = “Federica Bonifazi ha processato le foto con 3DF Zephyr” act/1/02/1 = “Alice Bordignon ha modellato con Blender” …
- La storia dell’OGGETTO ORIGINALE (ob00-ob08)
Queste triple descrivono l’oggetto fisico originale (la carta nautica del 1482):
act/1/ob00/1 = “Creazione dell’opera originale” (F28_Expression_Creation) act/1/ob08/1 = “Il museo conserva questo oggetto” (curating) itm/1/ob00/1 = L’item fisico originale exp/1/ob00/1 = L’espressione intellettuale wrk/1/ob00/1 = L’opera
URI pattern per ogni fase
Section titled “URI pattern per ogni fase”BASE = "https://w3id.org/changes/4/aldrovandi"
raw/ -> act/{nr}/00/1, mdl/{nr}/00/1, tsp/{nr}/00/1, lic/{nr}/00/1, apl-lic/{nr}/00/1rawp/ -> act/{nr}/01/1, mdl/{nr}/01/1, tsp/{nr}/01/1, lic/{nr}/01/1, apl-lic/{nr}/01/1dcho/ -> act/{nr}/02-04/1, mdl/{nr}/02-04/1, tsp/{nr}/02-04/1, lic/{nr}/02-04/1, ...dchoo/ -> act/{nr}/05-06/1, mdl/{nr}/05-06/1, tsp/{nr}/05-06/1, lic/{nr}/05-06/1, ...Dipendenze cumulative
Section titled “Dipendenze cumulative”raw/ -> solo metadati step 00rawp/ -> metadati step 00 + 01dcho/ -> metadati step 00 + 01 + 02 + 03 + 04dchoo/ -> metadati step 00 + 01 + 02 + 03 + 04 + 05 + 06Struttura output
Section titled “Struttura output”data/output/├── Sala1/│ └── S1-01-CNR_CartaNautica/│ ├── raw/│ │ ├── meta.ttl # step 00│ │ └── prov.nq│ ├── rawp/│ │ ├── meta.ttl # step 00 + 01│ │ └── prov.nq│ ├── dcho/│ │ ├── meta.ttl # step 00-04│ │ └── prov.nq│ └── dchoo/│ ├── meta.ttl # step 00-06│ └── prov.nq└── ...Domande
Section titled “Domande”Aldrovandi
Section titled “Aldrovandi”- Primary source e responsible agent li ho già chiesti vero?
- act/1/00/1: il primo 1 è il numero dell’oggetto? Il secondo cos’è?
- Io devo mettere sia metadati di digitalizzazione che sull’oggetto originale in meta.rdf, giusto? Mappare gli step 00-06 a raw-dchoo, è “facile”, ma come faccio per i ob00-ob08?
- Primary source e responsible agent
- Le tabelle CSV vanno caricate su Zenodo. Quello è la primary source
- Resp agent: il processo di Ari. Va definito. https://w3id.org/changes/4/agent/morph-kgchad-v{versione_software_arianna}
- act/1/00/1
- Se domani qualcuno fa un’attività di acquisizione per lo stesso oggetto ho l’attività di acquisizione 2. Nel nostro caso c’è solo la 1. è un sistema di estensione.