2026-01-13 core
La Novitade
Section titled “La Novitade”<div> <strong style="display: block; color: #1f2328;">arcangelo7</strong> <span style="font-size: 0.85em; color: #656d76;">Dec 27, 2025</span> <span style="font-size: 0.85em; color: #656d76;"> · </span> <a href="https://github.com/opencitations/oc_meta" style="font-size: 0.85em; color: #0969da; text-decoration: none;">opencitations/oc_meta</a></div>feat(fixer): add script to detect identifier schema mismatches
Scans RDF files directly to find identifiers where the declared schema does not match the value pattern (e.g., ISSN values marked as ORCID).
ORCID errati (7 casi)
Section titled “ORCID errati (7 casi)”Identificatori con formato ISSN/ISBN ma schema ORCID. Tutti appartenenti a entita BR (Journal/Book).
| ID Mismatch | Valore errato | Entita | Titolo | Valore corretto | Schema corretto |
|---|---|---|---|---|---|
| 06012393243 | 2790-9344 | br/06012054723 | Pakistan Journal Of Health Sciences | 2790-9344 | issn |
| 06012393328 | 1462-0324 | br/06012054834 | Rheumatology | 1462-0324 | issn |
| 06012393250 | 0962-1067 | br/06012054731 | Journal Of Clinical Nursing | 0962-1067 | issn |
| 06012393478 | 0277-1691 | br/06012055012 | International Journal Of Gynecological Pathology | 0277-1691 | issn |
| 06012393294 | 9783111692456 | br/06012054788 | Women In The Socratic Tradition | 9783111692456 | isbn |
| 06012387883 | 9783031963971 | br/06012050602 | Studies In Childhood And Youth | 9783031963971 | isbn |
| 06012387868 | 1724-6059 | ra/06030984957 | (Responsible Agent) | 1724-6059 | issn |
Verifica esterna:
- ISSN 2790-9344: confermato Pakistan Journal of Health Sciences
- ISSN 0962-1067: confermato Journal of Clinical Nursing
- ISBN 9783111692456: confermato De Gruyter
Tutte le corruzioni sono successive al 22 dicembre, data in cui è stato spento il server. Io me l’ero dimenticato e non ho stoppato Meta in tempo.
Soluzione: cancellare tutte le entità successive al 22 dicembre e riprocessarle.
Pensandoci meglio questa soluzione è rischiosa. Alla fine ho preferito rilanciare il processo da capo.
autoheal: image: willfarrell/autoheal:latest container_name: oc_meta_autoheal restart: unless-stopped network_mode: none environment: AUTOHEAL_CONTAINER_LABEL: all AUTOHEAL_INTERVAL: 30 AUTOHEAL_START_PERIOD: 120 volumes: - /var/run/docker.sock:/var/run/docker.sock - /etc/localtime:/etc/localtime:ro<div> <strong style="display: block; color: #1f2328;">arcangelo7</strong> <span style="font-size: 0.85em; color: #656d76;">Dec 20, 2025</span> <span style="font-size: 0.85em; color: #656d76;"> · </span> <a href="https://github.com/opencitations/oc_meta" style="font-size: 0.85em; color: #0969da; text-decoration: none;">opencitations/oc_meta</a></div>fix: add timeout to SPARQLClient to handle database unavailability
- Add timeout=3600 (1 hour) to all SPARQLClient calls in production code
- Add timeout=60 to all SPARQLClient calls in test code
- Update sparqlite to 1.1.0 which supports timeout parameter
- Add exit code checking in meta_process.py for child process failures
- Add wait_for_virtuoso utility for test database readiness
- Add database_unavailability_test.py to verify graceful failure handling
When the triplestore becomes unavailable, SPARQLClient now times out instead of hanging indefinitely, allowing proper error propagation.

feat: add timeout parameter to SPARQLClient [release]
Explain which specific system underpins the Paratext DB case study when it is first mentioned
Regarding the ParaText scenario, it is fairly obvious that editing in a database requires a user interface, this is not specific to the complexity of the domain. As a reader, I wonder whether there is another reason why this system is a good example for the contribution of this thesis. The argument about a provenance is clearer, and maybe that could be at the centre of the scenario in 3.2.
Nella narrativa attuale sembra quasi che Paratext sia un sistema preesistente a Heritrace e che sia stato utilizzato per far emergere dei requisiti che poi Heritrace ha soddisfatto. Questo crea dei fraintendimenti in entrambi i revisori. Di conseguenza ho reso più esplicito che OC Meta è il sistema preesistente che dimostra l’esistenza di barriere sistematiche su scala, mentre Paratext è servito come piattaforma di guerilla testing per validare se la soluzione proposta, cioè Heritrace, fosse in grado di risolvere quei problemi che pur si presentano anche in Paratext. In quest’ottica, la metodologia utilizzata rientra nel cosiddetto Design Science Research, un paradigma orientato alla risoluzione di problemi che mira a estendere i confini delle capacità umane e organizzative attraverso la creazione di artefatti nuovi e innovativi. Si oppone alla behavioural research che invece indaga comportamenti esistenti per elaborare nuove teorie. Noi partiamo da una teoria esistente per elaborare una soluzione.
The research follows a Design Science Research methodology \citep{hevnerDesignScienceInformation2004}, where the construction and evaluation of an artifact (HERITRACE) constitutes the primary contribution. Two case studies serve distinct methodological roles. OpenCitations Meta \citep{massariOpenCitationsMeta2024}, where the author participates as a contributor, provides independent validation that the identified barriers exist at scale in production systems. The ParaText Bibliographical Database was developed as an application case for HERITRACE, serving as a testbed for guerrilla testing \citep{nielsenUsabilityEngineering1993} and iterative refinement throughout the development process. This distinction is methodologically significant: OpenCitations Meta demonstrates the problem exists independently, while ParaText enables solution validation through guerrilla testing in a real-world scholarly context.
The RQ could be better developed, possibly breaking it down to sub-questions.
Why considering technically proficient users, since the RQ only targets domain experts, that are supposidely not technically savvy?
Prima:
This challenge motivates the research question: how can we enable domain experts to participate in semantic data curation while maintaining provenance documentation, tracking changes over time, supporting flexible customization, and integrating with existing RDF collections?
Dopo:
This challenge motivates two research questions addressing distinct operational phases:
RQ1: How can we design interfaces that enable domain experts to curate RDF data without requiring technical expertise, while maintaining provenance documentation and change tracking?
RQ2: How can technical staff perform one-time system configuration to adapt the curation environment to specialized domains, ensuring integration with existing RDF collections and flexible customization?
RQ1 addresses the continuous curation workflow where domain experts interact with semantic data daily. RQ2 addresses the initial configuration phase, performed once by technical staff, that prepares the system for domain-specific use.
Aldrovandi
Section titled “Aldrovandi”Cartelle che non rispettando il naming
| Categoria | Conteggio | Esempio |
|---|---|---|
| Non oggetto (materials, _files) | 8 | Sala1/materials |
| Sub-item con lettera (27a, 74b) | 16 | S2-27a-FICLIT_... |
| Separatore spazio | 1 | S2-39 - Vitello... |
| Prefisso speciale (PT, VS, s.n.) | 6 | S3-PT-DICAM_... |
| NR con underscore | 2 | S6-106_..., S6-114_115_116-... |
| Senza NR | 2 | S1-CNR_SoffittoSala1 |
| Sala 5 - Vetrina | 108 | S5-Vetrina 1 alto N... |
| Sala 5 - Manoscritto | 8 | S5-Manoscritto-FICLIT_... |
| Sala 5 - Altri (A, B, CNR) | 20 | S5-A alto sinistra... |
| TOTALE | 171 |
Riguardo questi
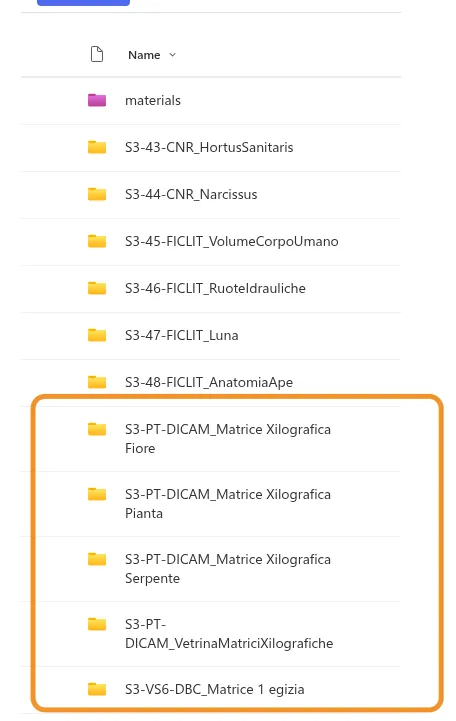
Qui qual è il numero?
stesso problema con robe tipo S5-B alto sinistra 2-CNR_Miocene, S5-Manoscritto-FICLIT_LexiconRerumInanimatarum ecc… Questi contengono le cartelle raw, rawp, dhco, e dhcoo
Domande
Section titled “Domande”- Contratto di ricerca
- Cosa uso come istante di generazione delle entità di provenance per Aldrovandi? Non ricordo https://w3id.org/changes/4/agent/morph-kgc-changes-metadata/1.0.1 va bene come agente responsabile?