2026-02-12 TAL vs OSTRICH
time-agnostic-library
Section titled “time-agnostic-library”
fix: handle language-tagged literals and safe triple removal
Add language tag comparison in match_literal to prevent false matches between literals with different xml:lang values. Materialize triple list before removal to avoid unsafe iteration on Dataset. Add xml:lang support when processing SELECT query results.
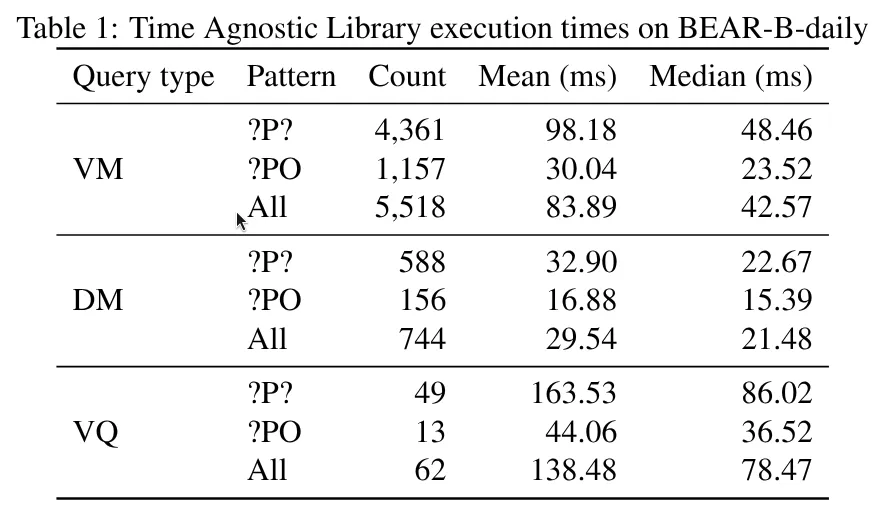
feat: add BEAR benchmark suite with QLever backend
Add BEAR-B-daily benchmark scripts for evaluating time-agnostic-library against published results. Includes data download, OCDM conversion, query parsing, benchmark execution, result verification, and analysis. Add rich and qlever dependencies.
feat: add include_all_timestamps option to VersionQuery
Cross-version VersionQuery now supports an include_all_timestamps parameter that fills gaps between snapshot timestamps by querying all prov:generatedAtTime values and carrying forward results from the nearest earlier timestamp
Also refactors Literal serialization in _query_reconstructed_graph to use .n3().
feat: switch VersionQuery results to SPARQL JSON bindings format
VersionQuery.run_agnostic_query() now returns Dict[str, List[Dict]] instead of Dict[str, Set[Tuple]], using the W3C SPARQL JSON Results bindings format which preserves type information (URI vs literal), language tags, and datatypes. Unbound OPTIONAL variables are omitted from bindings rather than appearing as None.
build!: migrate from Poetry to uv and drop Python 3.9
BREAKING CHANGE: Python 3.9 is no longer supported. Minimum required version is now Python 3.10.
docs: migrate documentation from Sphinx to Astro Starlight
refactor: optimize query performance and remove unused features
Cache datetime parsing with lru_cache, pre-sort timestamps outside loops, replace string concatenation with list join, and cache prov properties at class level. Remove _cut_by_limit, _hack_dates, and cache_triplestore_url references.
perf: replace pyparsing-based SPARQL UPDATE parser with regex
rdflib's parser.parseUpdate() uses pyparsing which takes 34.6s for an exemplar BEAR benchmark queries. The new regex-based parser handles the same OCDM query format in 2.2s (16x faster).
perf: replace ThreadPoolExecutor with ProcessPoolExecutor on Linux
Use forkserver-based ProcessPoolExecutor on Linux for true multi-core parallelism in entity reconstruction and delta identification. Fall back to ThreadPoolExecutor on Windows where fork is unavailable.
refactor: replace CONSTRUCT queries with SELECT for faster SPARQL execution
perf: simplify provenance query and remove DISTINCT from all internal queries
Use a lightweight SPARQL query with a single OPTIONAL when include_prov_metadata is False, skipping unnecessary joins and OPTIONAL clauses. Remove DISTINCT from all internal SELECT queries since results are consumed by Python sets. Replace pyparsing-based parseUpdate with regex-based _fast_parse_update in AgnosticQuery and DeltaQuery.
BREAKING CHANGE: get_state_at_time returns empty entity_snapshots dict when include_prov_metadata is False.
feat(benchmark): add OSTRICH comparison and ingestion timing
Add setup and benchmark runner for OSTRICH via Docker, enabling head-to-head comparison on the same hardware. Measure ingestion times for both OCDM conversion and QLever indexing.
perf: stream cross-version VersionQuery to avoid O(N) dataset copies
For isolated cross-version queries, fuse materialization and query execution: maintain one mutable graph per entity, apply deltas incrementally, and extract bindings at each step. This reduces memory from O(N * graph_size * entities) to O(graph_size + N * bindings_size).
feat: extract OCDM converter into reusable library module
Move conversion logic from benchmark script into src/time_agnostic_library/ocdm_converter.py with OCDMConverter class supporting both IC (independent copies) and CB (change-based) strategies. Refactor convert_to_ocdm.py as thin wrapper with --strategy ic|cb flag. Add documentation page for the new module.
perf: batch SPARQL queries and set-based reconstruction for VM/VQ/DM
Add thread-local SPARQLClient connection pooling to reuse TCP connections across queries. Batch provenance and dataset queries using VALUES clause to reduce per-entity round-trips. Run entity discovery and data fetching in parallel via ThreadPoolExecutor. Replace rdflib Dataset operations with Python set-based version reconstruction and direct triple pattern matching for single isolated patterns.
Optimize FILTER CONTAINS entity discovery by returning entities directly via specializationOf join. Batch DM provenance and existence queries. Remove VQ subprocess isolation in run_benchmark.py.
Add timing measurements and baseline comparison to verify_results.py (--save-baseline / --compare flags).

Non di solo Aldrovandi vive l’uomo
Section titled “Non di solo Aldrovandi vive l’uomo”
refactor: remove 98a/b/c folder grouping after unification
The S6-98a/b/c-DA-Calchi facciali colorati folders have been unified into a single S6-98 folder on SharePoint, removing the need for grouped entity mapping in the code
refactor!: generalize tool to support any OWL ontology
Replace SKG-IF-specific logic with a generic approach that supports any OWL ontology using the dc:description property pattern. The tool now accepts single files, directories, and URLs as input.
perf: replace rdflib Dataset with N3 string sets for internal state
Internal entity state is now stored as set[tuple[str, ...]] of N3-formatted strings instead of rdflib Dataset objects. Datasets are only materialized at public API boundaries. This eliminates rdflib's overhead for graph manipulation during version reconstruction, replacing Dataset.add/remove with set.add/discard and Dataset copy with set copy.
Domande
Section titled “Domande”- OC Spider