06-10-2022 Threadripper
Cosa ho fatto
Novità relative a oc_ocdm
- È ora possibile salvare e leggere file rdf zippati, sia in json-ld che in nquads. Questo comportamento è stato testato a fondo.
- Basta specificare a True il parametro zip_output nello Storer. Il default è False.
- Il Reader gestisce questo comportamento in automatico.
- I test vengono lanciati a ogni push e la coverage aggiornata.
- Ho portato la coverage dal 74% all’80%.
- Eseguire i test sui server di Microsoft ha nuovamente sollevato il problema relativo all’assenza di fuso orario nei tempi di generazione degli snapshot. Ne avevo parlato qui: https://github.com/opencitations/oc_ocdm/issues/15
- Ho temporaneamente risolto il problema convertendo i tempi in UTC solo nei test.
- L’esplosione nel consumo di memoria è causata dalle entità preesistenti e dalla cache dello storer di oc_ocdm. Se un entità esiste già, oc_ocdm carica in memoria l’intero file JSON contenente quell’entità, converte i dati in un ConjunctiveGraph, lo modifica e salva tale grafo in un dizionario le cui chiavi sono i percorsi dei file. Dopo aver fatto tutte queste modifiche, salva i nuovi file ciclando sulle chiavi, per evitare di scrivere due volte uno stesso file.
- Questo è un grosso problema, perché la memoria fa da collo di bottiglia al numero di processi che possono lavorare in parallelo.
- Mettere meno righe in ogni file CSV non è una soluzione, perché ci sono righe contenenti centinaia di autori, che da sole richiedono decine di GB di memoria (ad esempio, 10.1038/s41510.1038/s41586-019-1545-086-019-1545-0, con i suoi 559 autori).
- Rimuovendo la cache il consumo di memoria per la suddetta riga passa da 22 GB a 180 MB. Tuttavia, rimuovere la cache aumenta a dismisura il numero di operazioni di I/O, spostando il collo di bottiglia dalla memoria al disco.
- Soluzione: fare una rivoluzione copernicana, ovvero ciclare sui file di output anziché sulle entità da salvare.
- Individuare tutti i file da salvare e associare loro le entità ivi contenute.
- Per ciascun file, recuperare il grafo preesistente.
- Per ogni entità ivi contenuta, aggiornare il grafo.
- Salvare il file.
Novità relative a oc_meta
Ho provato a comprimere il file journal di Blazegraph, risparmiando così circa il 25% (53 GB→ 40 GB). Tuttavia, quando ho riavviato il processo, il dataset ha cominciato a crescere rapidissimamente, arrivando dopo soli 8000 file a 1,1 TB, una dimensione superiore a quella del file di journal a processo quasi completato, ovvero 500 GB con 60,000 file processati (ogni file contiene circa 1000 documenti).
- Applicando la compressione sul file da 1,1 TB la dimensione si è ridotta del 96%, passando a 53,7 GB.
- La dimensione del file journal senza applicare la compressione dopo 8000 file è di circa 75 GB.
Nuovo comando da terminale per zippare e unzippare i file individualmente e in maniera ricorsiva a partire da una directory e, facoltativamente, sostituire i file originali.
1
2
3
4python3 -m oc_meta.run.zip_process --operation [zip|unzip] \
--source SOURCE_DIR \
--destination DESTINATION_DIR \
--replace- Zippare i file RDF relativi a 10 milioni di documenti ha ridotto lo spazio occupato da 124 GB a 4,2 GB (-96.6%), senza impattare visibilmente sulla velocità del processo.
Ora OC Meta accetta un nuovo parametro di configurazione: zip_output_rdf, che se specificato a True zippa i file JSON in output. I file in input devono già essere stati zippati con il comando al punto precedente.
Novità relative all’articolo per JASIST
- Ho risposto a tutti i commenti di Silvio
- Dopo svariate ore trascorse a debuggare i fallimenti di arXiv nel compilare il file .tex, ho caricato un PDF generato salvando come PDF il PDF generato da Overleaf, che essendo basato su un’immagine non viene riconosciuto come PDF generato tramite LaTeX da arXiv.
- Per qualche ragione questo hack funziona generando il PDF con Firefox, ma non con Chrome (Ubuntu).
- Per ottenere l’URL di arXiv bisogna aspettare il 07-10-2022 alle 00:00:00 GMT.
Domande
Domande relative a oc_ocdm
Aggiungere il fuso orario ai tempi di generazione degli snapshot potrebbe creare incoerenze con la provenance esistente?
oc_ocdm al momento può leggere tutte le principali serializzazioni di RDF, ma scrivere solo in json-ld, n-triples e n-quads. Inoltre, se il formato di output è diverso da json-ld, i dati vengono salvati in n-quads in file con estensione “.nt”. In altre parole, qualunque sia il formato di output specificato, l’output è in uno di questi due formati. È un comportamento voluto?
Ho notato che Blazegraph non rilascia mai la memoria allocata. Qualunque sia l’heap-size, la memoria allocata continua a salire finché non lo raggiunge, dopodiché Blazegraph smette di rispondere.
- Esiste anche una discussione sull’argomento, ma senza una risposta (alla fine l’OP si è arreso ed è passato a Stardog): https://sourceforge.net/p/bigdata/discussion/676946/thread/470a9e36/
Ipotesi
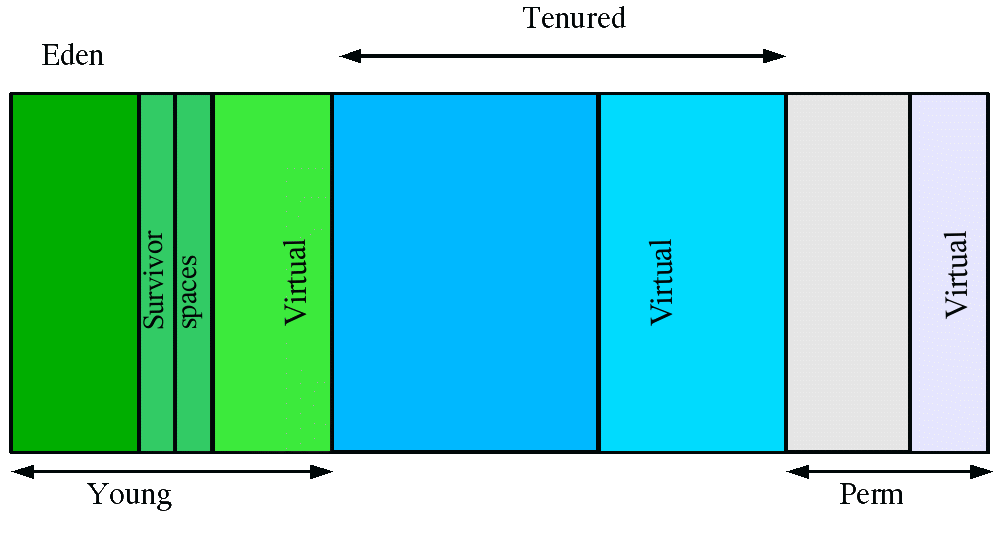
Java usa tutto l’heap size disponibile per attivare il garbage collector meno volte possibile
- Quanto un nuovo oggetto viene creato finisce nell’Eden space.
- Quando l’Eden space è pieno il GC Young libera l’Eden space e copia tutto in uno dei due Survivor space. Uno dei due è sempre pieno, l’altro sempre vuoto.
- Successivamente, gli oggetti ancora attivi nel Survivor space vengono copiati nell’altro survivor space. Se degli oggetti vengono spostati troppe volte da un survivor space all’altro (8 di default), vengono spostati nel tenured space.
- Quando il tenured space è pieno si attiva il Full GC.
Forse Blazegraph si blocca a causa dell’attivazione del Full GC.
Altro
- La rebuttal letter la metto su Zenodo e non su Qeios, giusto?