27-01-2022
Cosa ho fatto
- Risolto un bug per cui la presenza del carattere nullo (\0) sollevava un’eccezione nel modulo csv. Tale carattere viene ora rimosso immediatamente all’apertura del file e non durante il processo di Meta.
- Confermo che l’archivio del dump di Crossref di gennaio viene letto correttamente.
- Novità relative al processo su Crossref preliminare a Meta:
I nomi degli autori e degli editor vengono puliti dai caratteri riservati dei CSV di Meta (parentesi quadre e ‘;’), più altri caratteri come il punto di domanda. Sono ammessi il punto preceduto da una lettera e lo spazio singolo, purché interno al nome. Inoltre, i trattini vengono normalizzati.
- ‘Bernacki, Edward ].’ → ‘Bernacki, Edward’
- ‘Zima, Tom??&OV0165’ → ‘Zima, Tom&OV0165’
- ‘Boezaart, Andr[eacute]‘ → ‘Boezaart, Andreacute’
- ‘Albers\u2010Miller, Nancy D.’ → ‘Albers-Miller, Nancy D.’
Gli intervalli di pagine vengono puliti tramite questa espressione regolare:
1
2pages_separator = [^A-Za-z\d]+(?=[A-Za-z\d]+)
pages = '-'.join(re.split(pages_separator, x['page']))-
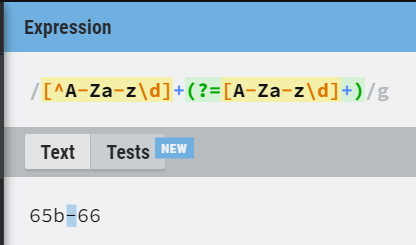
Come puoi notare, lo split permette la presenza non solo di numeri, ma anche di lettere dell’alfabeto, perché a volte gli intervalli di pagine le contengono (vedere la sezione Domande di oggi per approfondire).
-
In precedenza, crossrefProcessing ignorava il campo ‘name’ all’interno dei campi ‘authors’ ed ‘editors’ di Crossref. Quel campo viene utilizzato sia nel caso in cui l’autore sia un’organizzazione, sia per schiacciare in un unico campo nome e cognome di una persona. Ad esempio:
- “name”: “ASA Standing Advisory Committee:” https://api.crossref.org/works/10.1161/hs0102.101262
- “name”: “Caterina Foti” https://api.crossref.org/works/10.1034/j.1600-0536.2002.460517.x
Ora anche quel campo viene catturato e viene sottoposto al processo per l’individuazione dell’ORCID sulla base del DOI e del cognome. Nello specifico, viene considerato come cognome l’ultimo elemento della stringa separato da spazio. Non è un approccio infallibile: ha successo per nomi come ‘Caterina Foti’, fallisce per nomi come ‘Silvia Di Pietro’, dove il cognome è ‘Di Pietro’ e non ‘Pietro’. Tuttavia, non penso si possa fare di meglio.
Le entità HTML vengono risolte per il titolo, autori, editor e venue.
I nomi dei publisher sono stati sostituiti con quelli autorevoli ricavati interrogando Crossref.
Se il campo ‘member’ non è presente, l’id del publisher e il suo nome vengono cercati tramite il prefisso del DOI.
Ho integrato lo script extract_crossref_publishers in Meta sotto la categoria “plugins” e l’ho documentato nell’apposita sezione del README. Lo script si lancia come tutti gli altri, quindi:
1
python -m meta.run.crossref_publishers_extractor --output <PATH>
Nel caso in cui la venue contenga elementi tra parentesi quadre che non sono id, ma che matchano il pattern degli id, solo tali parentesi quadre vengono sostituite da parentesi tonde (vedere la sezione Domande di oggi per approfondire).
- Aggiunti vari caratteri alla lista dei trattini ambigui da sostiture con \u002D, ovvero:
- In Meta, ho ripristinato le espressioni regolari semplici, che non gestiscono eccezioni.
- Il crash dovuto all’assenza di un determinato MetaID nell’indice delle venue è stato sollevato anche al di fuori del sistema di cache, quindi non è causato dalla cache. Sto cercando di capire cosa lo causi, ma non ho ancora trovato l’origine del problema:
- Aggiunti dei test a indexer e vvi_action, funzioni coinvolte nella generazione e lettura dell’indice delle venue.
- Risolto un bug di __is_contained_in_venue che si sollevava in caso di issue contenuto direttamente nella rivista, senza volume. Aggiunto un test che riproduce quel caso.
- La dimensione massima di un campo in un csv viene raddoppiata in loop laddove 128 kb non siano sufficienti, dopodiché immediatamente ripristinata.
Domande
- Domande relative al pre-processing del dump di Crossref:
A me non convince l’idea di eliminare dai nomi tutti i caratteri diversi dalle lettere, numeri, punti preceduti da lettera ed e commerciale. Questa scelta presuppone che qualcuno conosca tutti i caratteri ammessi in un nome di persona.
- Occorre anzitutto conoscere tutti gli alfabeti del mondo e quale delle lettere dei vari alfabeti sono effettivamente usate per i nomi di persona.
- Basic Latin, Latin-1 Supplement, Latin Extended-A, Latin Extended-B, Spacing Modifier Letters, Combining Diacritical Marks, Greek and Coptic, Cyrillic, Cyrillic Supplement, Armenian, Hebrew...
- Faccio un esempio di domanda alla quale occorrerebbe rispondere per prendere una scelta simile: le lettere africane per i click (ǀ, ǁ, ǂ e ǃ) si possono usare nei nomi di persona?
- Posso anche creare un’espressione regolare che catturi tutti gli alfabeti nella maniera più ampia possibile (’[A-Za-zÀ-ÖØ-öø-ÿĀ-ňƀ-njΑ-ω…]’), ma non mi sembra una soluzione robusta.
- Non solo, ci sono altri caratteri, che non sono lettere, ammissibili in un nome di persona:
- Tutti i caratteri simili all’apostrofo (e.g. O’Connel)
- Il trattino (e.g. Mun, Ji-Hye)
- Alla fine ho deciso di eliminare dai nomi solo quei caratteri che potrebbero rompere le espressioni regolari, ovvero “**;”, “[” e “]**”, rimanendo agnostico su tutti gli altri. Infatti, ho notato che creando delle whitelist gli errori introdotti sono di gran lunga superiori a quelli risolti, perché la varietà nei nomi è immensa e non posso verificarli tutti. Cosa ne pensi?
- Occorre anzitutto conoscere tutti gli alfabeti del mondo e quale delle lettere dei vari alfabeti sono effettivamente usate per i nomi di persona.
Sei d’accordo sul consentire la presenza di lettere negli intervalli di pagine? Ecco un paio di esempi:
- “page”: “G28” (https://api.crossref.org/works/10.1039/b204527n)
- “page”: “583b-583” (https://api.crossref.org/works/10.1001/archderm.108.4.583b)
In entrambi i casi, il dato è corretto.
Nell’articolo con DOI 10.1080/13576280050074426 l’autore risulta avere nome ’Hannes’ e cognome ‘G. Pauli, Kerr L. White, Ian R. McW’. Chiaramente, si tratta di tre autori diversi schiacciati in un unico campo ‘family’. Cosa ne pensi?
- La presenza della virgola nei campi ‘given’ o ‘family’ si verifica in 119’929 documenti e 177’235 autori del dump di gennaio.
- A volte la virgola separa persone diverse, a volte separa un nome da un cognome divisi in campi diversi, come in
{"given": "Luca," "family": "Cerino"}(https://api.crossref.org/works/10.1097/iae.0000000000003387)
Considerare il campo ‘name’ degli autori dei lavori di Crossref introduce un’eccezione alla regola che vuole la virgola sempre presente nei nomi degli autori. Se d’accordo sul considerare il campo ‘name’ e introdurre questa eccezione?
Ci sono alcune venue che sono registrate con elementi tra parentesi quadre, a volte contenenti anche i due punti, per esempio:
- “container-title”: [“Cerebrospinal Fluid [Working Title]”] (https://api.crossref.org/works/10.5772/intechopen.98910). Era presente nel dump di gennaio 2022 ma è stato modificato successivamente, rimuovendo ‘[Working Title].’
- Esiste una venue di nome “troitel’stvo: nauka i obrazovanie [Construction: Science and Education] [issn:2305-5502]”. Il nome della venue contiene sia parentesi quadre che due punti.
Se d’accordo sul rimuovere tutto ciò che si trova tra parentesi quadre, assumendo che si tratti di tag che non fanno parte del nome della venue? In alternativa, si potrebbero sostituire con delle parentesi tonde solo quelle parentesi quadre che matchano l’espressione regolare degli id. Se non posso rimuovere o modificare le parentesi, devo necessariamente complicare le espressioni regolari per catturare gli id.
Cosa fare con quegli autori di cui è presente solo il given name? Ad esempio:
- {‘given’: ‘Aanchal’, ‘sequence’: ‘additional’, ‘affiliation’: [{‘name’: ‘Department of Biotechnology; Thapar University; Patiala Punjab 147 004 India’}]} (https://api.crossref.org/works/10.1002/ep.12004)
- Questo autore va salvato come ‘, Aanchal’? Con la virgola prima del nome.
- Se si basa il sistema di cache solo sui CSV grezzi in input, nel momento in cui il processo si interrompe e poi riprende, la numerazione delle entità avrà dei buchi. Per esempio, ci sarà br/060100 ma non ci sarà br/060101 sul triplestore, perché il +1 è stato registrato solo nell’info_dir prima del crash. Questo non è un problema, giusto?