30-08-2022 HDD = bottleneck
Cosa ho fatto
Novità relative a OC Meta
- Il processo su oc-ficlit è diventato troppo lento. Ho scoperto che il collo di bottiglia è l’HDD, perché facendo proseguire il lavoro al mio PC su SSD la velocità è aumentata di ordini di magnitudo (M.2 Nvme PCIe 4.0, 5000 MB/s in lettura e 4400 MB/s in scrittura).
Per sicurezza, ho ripetuto il test sempre sul mio PC su HDD e ho confermato che il problema è l’HDD.
Nella documentazione di Blazegraph si legge:
Blazegraph depends on fast disk access. Low-latency, and high IOPs disk is key to high performance. SSD offers a 10x performance boost for the Journal in the embedded, standalone, and highly available replication cluster deployment modes when compared to SAS or SATA disks. In addition, SATA disks are unable to reorder writes. This can cause a marked decrease in write throughput as the size of the backing file grows over time. Since 1.3.x, we have introduced a cache compaction algorithm into the Journal that significantly reduces IOs associated with large write transactions. This makes SATA more viable, but the performance gap to SSD is still an order of magnitude for query. SAS disks can reorder read and write operations, but still have a large rotational latency and lower seek times when compared to SSD. For enterprise class deployments, you can use either PCIe flash disk or SSD in combination with the HAJournalServer (high availability). AWS now offers an SSD backed instance that is a good match for Blazegraph.****
Utilizzare hard disk meccanici per un triplestore colossale come OC Meta renderà molto più lente anche le API. Finché il triplestore è piccolo non si notano differenze tra SSD e HDD, ma le differenze aumentano mano a mano che aumentano le pagine del file journal.
Come compromesso, si potrebbe mettere solo il triplestore su SSD e il resto dei file su HDD. Al momento, dopo aver processato il 20% dei file, il file journal pesa 100 GB. Chiaramente l’SSD da 439G attuale su oc-ficlit non va bene, bisognerebbe acquistarne uno nuovo, possibilmente uno che vada su linea PCIe per la maggior velocità possibile.
- Per venire incontro a questa esigenza, ho inserito un parametro di configurazione opzionale che permette di scegliere la cartella di output contenente i file rdf, dato che è di gran lunga la più pesante e ha senso tenerla su HDD.
- In questo momento il processo sta proseguendo sul mio PC con triplestore su SSD e JSON su HDD. In questo modo, il processo è molto più lento che avendo tutto su SSD, ma comunque molto più veloce che avendo tutto su HDD.
- Risolto un bug per cui il Curator crashava se un metaid era stato inserito nel dizionario delle entità conflittuali e non in quello delle entità non conflittuali. Dato che non ho trovato alcun vantaggio nel distinguere i due dizionari, ho eliminato il dizionario delle entità conflittuali e unificato la gestione delle due tipologie di entità, conservando soltanto l’aggiornamento dei log.
Novità relative all’articolo per JASIST
Ho gestito il 70% dei commenti dei revisori (modifiche all’articolo + lettera di risposta).
Dopo lunghe peregrinazioni sono approdato alla seguente tabella comparativa
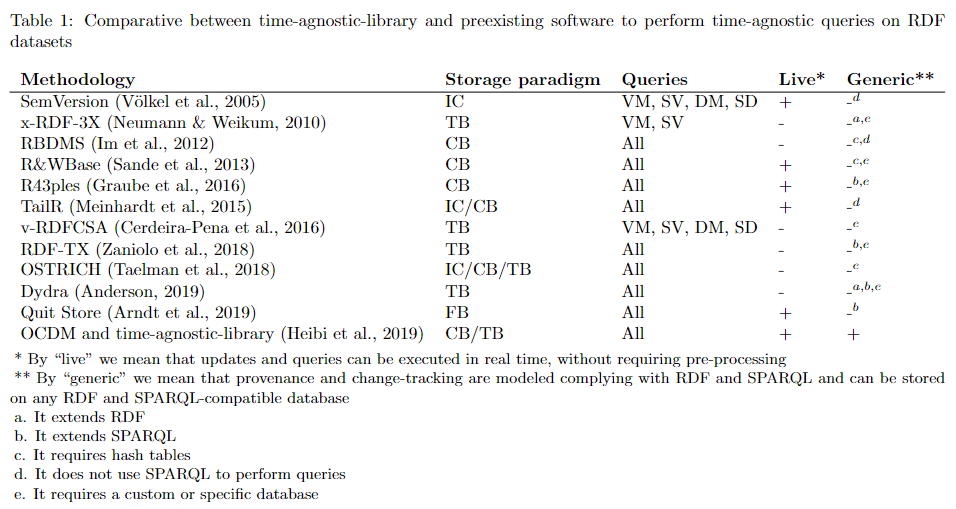
Questa tabella risolve numerosi problemi:
- Sintetizza quelle che originariamente erano tre tabelle distinte (con buona pace di JASIST e delle sue 7000 parole massime):
- Quella su come rappresentare la provenance senza violare RDF e SPARQL
- Quella sulle politiche di archiviazione
- Quella sulle tipologie di query
- Evidenzia la vera innovazione di time-agnostic-library, ovvero la sua genericità. Infatti, da ulteriori letture era emerso che time-agnostic-library non fosse l’unico software a consentire tutte le query live, caratteristica comune anche a tutti i sistemi ispirati a Git (R&WBase, R43ples e Quit Store)
- È coerente con altre due comparative presenti in letteratura, che non conoscevo e che i revisori mi hanno chiesto di citare (10.3233/SW-210434 e 10.1016/j.websem.2018.08.001).
- Adotta una definizione più precisa di “live”, per rispondere a un revisore che aveva obiettato che time-agnostic-library non è live perché usa dei triplestore.
- Aggiunge alla comparativa R43ples, TailR, Dydra, Quit Store e RDF-TX.
- Aggiunge la politica di archiviazione fragment-based (FB), ovvero salvare soltanto ciò che cambia (non i cambiamenti), a diversi livelli di granularità a seconda dei requisiti (grafi, sottografi, entità).
- Esplicita nella revisione della letteratura quali sono i limiti della letteratura, come chiesto da Reviewer #3.
- Sintetizza quelle che originariamente erano tre tabelle distinte (con buona pace di JASIST e delle sue 7000 parole massime):
Sto aggiornando il codice dei benchmark
- Per calcolare la baseline per ciascuna query, ovvero tempo di esecuzione sullo snapshot corrente e numero di snapshot.
- Materializzazione di tutte le versioni di un’entità. Il numero di snapshot corrisponde al numero di snapshot dell’entità
- Materializzazione di un intervallo della storia di un’entità. Il numero di snapshot corrisponde al numero di snapshot successivi all’intervallo più quelli compresi nell’intervallo.
- cross-version query. Il numero di snapshot corrisponde alla somma degli snapshot di tutte le entità soggetto ****convolte nella query.
- single-version query. Il numero di snapshot corrisponde alla somma degli snapshot di tutte le entità soggetto ****coinvolte nella query, solo se compresi o successivi all’intervallo temporale considerato.
- Per quanto riguarda le query sui delta il numero di snapshot non è rilevante, perché a essere processati non sono gli snapshot, ma le entità al fine di trovare gli snapshot, quindi la prospettiva è ribaltata. A pesare è quindi il numero di entità coinvolto nella query.
- Per calcolare la baseline per ciascuna query, ovvero tempo di esecuzione sullo snapshot corrente e numero di snapshot.
Aggiornando il codice, mi sono accorto di alcuni comportamenti indesiderati in time-agnostic-library:
- Le query single-version recuperavano dalla cache l’intera storia delle entità anziché solo quella entro l’intervallo considerato.
- Non c’è ragione di processare gli URI corrispondenti ai tipi nelle query.
- Non c`è ragione di esplicitare variabili che sono punti morti, ovvero che non si trovano come soggetto in un altro triple pattern all’interno della query.
- Le informazioni sull**’intervallo** in cache vengono ora eliminate quando tutta la storia dell’entità viene salvata in cache.
- Data la necessità di calcolare il numero di snapshot coinvolti in una single-version query, ho aggiunto la version query secondo la classificazione dei query atoms (ritorna il risultato su quella versione più informazioni sulle altre versioni esistenti). Alcuni caveat:
- Se l’utente chiede informazioni su altri snapshot oltre a quelli puntati dalla sua query non può avvalersi contemporaneamente della cache, perché la cache non contiene quelle informazioni per pesare il meno possibile.
- Se l’utente chiede informazioni su altri snapshot ma la sua query è su tutte le versioni, tali informazioni sono un insieme vuoto.
Domande
Domande relative a OC Meta
- Qual è la differenza tra bigdata.jar e blazegraph.jar?
Domande relative a Performing live time-traversal queries on RDF datasets
- Reviewer #3 ha chiesto spiegazioni sul perché RDF* sia stato classificato come non scalabile. Gli ho risposto che questa categorizzazione è stata tratta da (Sikos & Philp, 2020), dove “scalabile” è definito come “non causa di esplosione di triple” e dove RDF* è considerato non scalabile, senza però spiegare perché. Effettivamente, neanch’io capisco perché RDF* non dovrebbe essere scalabile.
- Non ricordo se l’OCDM consenta i blank nodes all’interno delle query SPARQL di update. Direi di no.
Altro
- La TPDLlica email
- OC Ontology su FAIRSharing.org. Il DOI?