06-05-2022 oc_meta è partita
Cosa ho fatto
Meta ha lavorato ininterrottamente per 70 ore. Ecco il risultato:
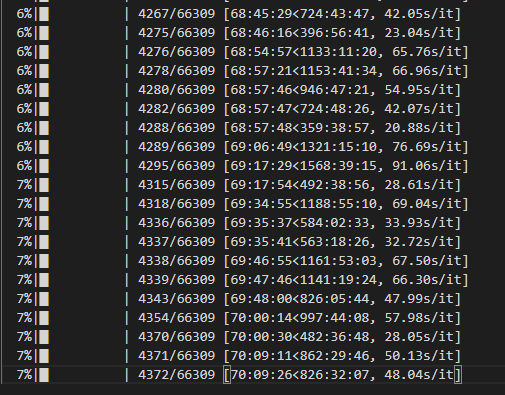
Ha utilizzato 16/24 processi.
Ecco lo storage occupato dopo 3000/66309 file processati (inclusi i risultati del preprocessing):
- Se lo spazio occupato continuerà ad aumentare in maniera lineare, 2 TB non basteranno:
- 110.898 x 22.103 = 2,451 GB
- Tuttavia, CSV e indici servono solo per debug, si possono rimuovere o spostare altrove.
- Se lo spazio occupato continuerà ad aumentare in maniera lineare, 2 TB non basteranno:
Il consumo di RAM oscilla tra 20/67 GB a 63/67 GB.
- oc_ficlit può portare a termine il processo senza problemi, ma oc_meta rende il server di test inutilizzabile per altri carichi medio-pesanti.
- La soluzione che ho trovato è rendere Meta stoppabile in qualsiasi momento e senza perdere la congruenza tra dati e triplestore, come spiegato nel prossimo punto.
Ho potenziato il sistema di cache nel caso in cui oc_meta debba operare per molto tempo:
- Ogni 1000 file processati, l’output viene salvato in un archivio.
- In pratica, anziché avviare la pool di processi sulla totalità dei file da processare, i file di input vengono divisi in chunk da 1000. Quindi vengono lanciate tante pool quanti sono i chunk.
- Al termine di ogni pool, il risultato viene salvato in un archivio.
- Ogni archivio contiene triplestore e file perfettamente allineati. Se il processo si interrompe, basta rilanciarlo sull’archivio più recente per essere sicuri che triplestore e file rimangano congruenti.
- Requisiti:
- Il triplestore si deve trovare nella stessa directory base che contiene anche i file rdf.
- Questo sistema funziona solo su UNIX, perché su Windows non è possibile zippare i file del triplestore, in quanto bloccati da un altro processo (Java).
- L’input deve contenere più di 1000 file, altrimenti ci sarà un solo chunk contenente tutti i file di input.
- Ogni 1000 file processati, l’output viene salvato in un archivio.
Dividere i CSV in input non solo sulla base del numero di righe, ma cercando anche di raggruppare il più possibile le br con stessa venue nello stesso file ha permesso di ridurre il numero di entità da preprocessare.
- Da 3,799,958 entità tra venue, volume e issue si è passati a 942,321.
- Si sono anche ridotti gli agenti responsabili e i publisher da preprocessare
- Agenti responsabili: da 2,662,497 a 2,556,831
- Publishers: da 14,993 a 6,969
Ora Meta è una libreria.
Si installa tramite
pip install oc_meta- A proposito, Meta ora si chiama oc_meta. La libreria “meta” esisteva già e oc_meta è coerente con la nomenclatura di altre librerie di OC, come oc_graphenricher e oc_ocdm.
Dipendenze, installazione, virtualenv e pubblicazione si possono gestire tramite poetry.
I test si lanciano tramite
poetry run test- Se Blazegraph non è presente nella directory, viene automaticamente scaricato e lanciato prima di eseguire i test.
Mi è piaciuta moltissimo l’idea di Giuseppe di far lanciare automaticamente i test a GitHub su varie versioni di Python. Ora questo workflow è presente anche su oc_meta.
Per quanto riguarda oc_ocdm e il multiprocessing:
- Rendere la classe thread-safe tramite multiprocessing.Lock è sufficiente in multi-threading, ma non in multi-processing, perché i lock non sono condivisi tra i processi.
- Dopo diversi confronti con Giuseppe e Simone, ho adottato la soluzione dei file .lock di py-filelock.
- Dato che questi file .lock non vengono cancellati su UNIX, Meta li cancella all’inizio e alla fine del processo. Li cancella all’inizio perché, se un processo crasha, i lock non vengono rilasciati.
Bugfix su oc_meta:
- Il merge tra due venue interne allo stesso CSV non teneva in considerazione i volumi e gli issue.
- Il tipo della venue di una br di tipo report series non veniva correttamente mappato a series, poiché “report series” veniva appiattito in “series ”all’inizio del workflow.
Non ho utilizzato il metodo
import_entity_from_triplestoredi oc_ocdm per recuperare un preexisting_graph perché esso non si limita a eseguire il CONSTRUCT, ma manipola il risultato trasformandolo in un GraphSet. Tale operazione è assai dispendiosa, oltre che superflua per Meta, quindi ho preferito creare un altro metodo apposito che esegua solo il CONSTRUCT all’interno di Meta.Novità relative a time-agnostic-library:
- La libreria è ora pienamente compatibile con Apache Jena Fuseki.
- Il sistema di cache è ora drasticamente più efficiente per quanto riguarda la prima esecuzione delle query non ancora in cache:
- La cache viene aggiornata una volta sola e non a ogni entità ricostruita come in precedenza. In questo modo, per ogni query agnostica sul tempo, avviene un solo collegamento al triplestore di cache per quanto riguarda l’upload.
- Tutte le computazioni per ricostruire il passato delle entità avvengono ora su grafi salvati in RAM. In precedenza, l’allineamento temporale dei grafi richiedeva delle query al triplestore di cache.
- Non è necessario appoggiarsi al triplestore se la query riguarda il grafo di una singola entità. Infatti, se il grafo è piccolo, fare query sulla RAM è più veloce.
- Viceversa, il triplestore di cache viene ancora utilizzato per la query finale, quella agnostica sul tempo sugli interi grafi temporali.
Domande
- Avrei bisogno di quanto più contesto e background possibile per quanto riguarda il rapporto tra EXCITE e OpenCitations.
- Posso usare Scrutinizer per analizzare la coverage delle mie librerie sulla repo di OpenCitations? Se sì, ho bisogno dell’autorizzazione di un proprietario dell’organizzazione.