30-01-2025 Bug storici di Meta risolti
Meta
Ho individuato un bug nella classe che preprocessa i Responsible Agents. Il problema riguardava il contatore per i nuovi identificatori, che non considerava il supplier prefix. Questo è accaduto dopo la modifica per usare Redis al posto dei file per i contatori: la funzione di incremento non era aggiornata, risultando comunque retrocompatibile e senza far fallire i test. Fortunatamente, ho cominciato a usare il Redis durante i merge, dove non serviva alcun preprocessing per il multiprocess, quindi non dovrebbero esserci state ripercussioni sul dataset finale.
Implementato nuovo script di verifica per i risultati di Meta. Verifica i risultati del processo di Meta analizzando i file CSV di input. Effettua controlli sugli identificatori verificando la loro presenza nel triplestore, l’esistenza nei dati e nella provenance nei file ZIP e identifica eventuali duplicati di OMID.
Rilevata la presenza di un issn con due OMID. L’OMID duplicato non esisteva nella versione precedente e deve essere stato generato durante la fase di preparazione al multiprocess, pertanto ho scritto un test che verifica esattamente se questa casistica, ovvero la duplicazione di identificativi con l’identificativo già esistente, la creazione di un nuovo identificativo con valore letterale identico al primo ma con il datatype e purtroppo però non sono riuscito a riprodurre il problema perché non viene generato, almeno in fase di test, nessun duplicato.
Forse ho trovato il problema
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38def __query(self, query, return_format = JSON):
self.ts.setReturnFormat(return_format)
self.ts.setQuery(query)
tentative = 3
result = None
while tentative:
tentative -= 1
try:
result = self.ts.queryAndConvert()
return result
except Exception:
sleep(5)
return result
# Se falliscono tutti e 3 i tentativi il risultato è None!!!
def __query(self, query, return_format = JSON):
"""Execute a SPARQL query with retries and exponential backoff"""
self.ts.setReturnFormat(return_format)
self.ts.setQuery(query)
max_retries = 5 # Aumentiamo il numero di tentativi
base_wait = 5 # Tempo base di attesa in secondi
for attempt in range(max_retries):
try:
result = self.ts.queryAndConvert()
return result
except Exception as e:
wait_time = base_wait * (2 ** attempt) # Exponential backoff
if attempt < max_retries - 1: # Se non è l'ultimo tentativo
sleep(wait_time)
else:
# Ultimo tentativo fallito, logghiamo l'errore e solleviamo un'eccezione custom
error_msg = f"Failed to execute SPARQL query after {max_retries} attempts: {str(e)}\nQuery: {query}"
print(error_msg) # Log dell'errore
raise Exception(error_msg)Ho allora provato a rimettere in piedi lo snapshot precedente di Meta e vedere se rilanciando con gli stessi dati si riverifica lo stesso identico problema. Si è riverificato con lo stesso ID!
Ho quindi scoperto che il problema si verifica quando la risorsa bibliografica è duplicata. In quel caso viene duplicato anche l’identificatore e questo certamente è un bug. Allora ho esteso il test precedentemente creato per riprodurre il problema e sono finalmente riuscito a riprodurlo.
Ecco il bug
1
2
3
4
5
6
7
8
9
10
11sparql_match = self.finder_sparql(idslist, br=br_ent, ra=ra_ent, vvi=vvi_ent, publ=publ_entity)
# if len(sparql_match) > 1:
# return self.conflict(idslist, name, id_dict, col_name)
# elif len(sparql_match) == 1:
if sparql_match:
existing_ids = sparql_match[0][2] # Errore!!!
# Dovrebbe essere
existing_ids = []
for match in sparql_match:
existing_ids.extend(match[2])Il bug era sorto nel momento in cui avevamo deciso di semplificare la gestione delle entità conflittuali in maniera tale da selezionare arbitrariamente il primo dei risultati che matchavano con un certo identificatore anche in presenza di eventuali conflitti, scelta che avevamo fatto per evitare di creare nuovi duplicati. Tuttavia, mi ero scordato di considerare la possibilità che nei match successivi al primo ci fossero identificatori assenti nel primo, mentre stavo considerando soltanto gli identificatori del primo match. Ecco perché venivano generati nuovi identificatori.
In un secondo momento si è riverificato lo stesso problema, ma questa volta a partire da una riga di input nella quale il campo ID era vuoto ed era popolato soltanto il campo venue e issue con il tipo di risorsa bibliografica indicato a journal issue. In questo caso l’identificatore che ha portato alla generazione di due omid era un ISSN della venue.
1
2"","","","","BMJ [issn:0267-0623 issn:0959-8138 issn:1468-5833 issn:0007-1447]","284","6318","","journal issue","BMJ [crossref:239]",""Anche in questo caso ho rilevato la presenza di due venue duplicate che tuttavia non avevano a monte nessun identificatore in comune e si sono rivelate duplicate solo a seguito di questa nuova ingestione. Tuttavia questo continua a non spiegare come mai si è stato creato un identificatore nuovo anziché riutilizzare quello già esistente come previsto. Ho inoltre notato la presenza di volumi duplicati, sia duplicati perché presenti, cioè duplicati intendo con lo stesso numero, sia duplicati perché presenti una volta senza datatype e una con il datatype che duplicati con lo stesso identico valore letterale.
Ho quindi ricreato lo snapshot precedente e il problema si è verificato di nuovo per lo stesso identificatore, mostrandomi che il problema è deterministico. Ora resta da capire cosa lo determina.
Finalmente ho capito che il problema si verifica combinando queste due righe.
1
2"issn:1756-1833","BMJ","","","","","","","journal","BMJ [crossref:239]",""
"","","","","BMJ [issn:0267-0623 issn:0959-8138 issn:1468-5833 issn:0007-1447]","284","6318","","journal issue","BMJ [crossref:239]",""Sul triplestore esiste già una venue con issn:1756-1833 issn:0959-8138 issn:1468-5833 issn:0007-1447 e una seconda venue distinta con identificatore issn:0267-0623. In pratica è grazie a questo CSV che impariamo che le due venue in realtà sono la stessa venue e vanno fuse. Allora, non mi aspetto che Meta si occupi di fondere le due venue ma sicuramente mi aspetto che innanzitutto non crei una nuova entità conflittuale e in secondo luogo riutilizzi l’URI associato a issn:0267-0623.
Ho quindi ricreato la medesima situazione in un test dedicato e sono riuscito a riprodurlo.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22for identifier in idslist:
if identifier not in id_dict: # Ecco il bug
self.__update_id_count(id_dict, identifier)
# id_dict associa le br agli id per evitare di ripetere le stesse query,
# ma in questo caso alla br non è associato uno degli id perché appunto
# la connessione tra le due br si scopre da questo CSV
# Soluzione: dare un'occhiatina al triplestore (tanto i dati rilevanti sono già
# tutti in locale) prima di creare un nuovo id.
def __update_id_count(self, id_dict, identifier):
# Prima di creare un nuovo ID, verifichiamo se esiste già nel triplestore
schema, value = identifier.split(':', maxsplit=1)
existing_metaid = self.finder.retrieve_metaid_from_id(schema, value)
if existing_metaid:
id_dict[identifier] = existing_metaid
else:
count = self._add_number('id')
id_dict[identifier] = self.prefix + str(count)Mi sono accorto che rilanciando un processo di Meta due volte sullo stesso file porta a nuove query SPARQL di update, cosa che in teoria non dovrebbe accadere. Allora ho indagato queste query SPARQL e mi sono accorto che volumi e issue vengono creati a ogni esecuzione. Questo mi ha fatto sospettare che non vengano deduplicati.
- Ho creato dei test per riprodurre il problema. In particolare, ho creato un test che testa la deduplicazione di volumi e issue all’interno del file CSV e un altro che testa la deduplicazione di volumi e issue già presenti sul database. Il primo passa, il secondo fallisce, dimostrando che il problema c’è eccome.
- Il problema si verificava perché da qualche tempo a questa parte io non sto più facendo query SPARQL per ogni singola deduplicazione ma sto raccogliendo dal triplestore in un colpo solo all’inizio tutte le informazioni pertinenti per fare la deduplicazione e risolvendo in maniera ricorsiva tutte quanti gli identificatori e eventuali risorse collegate a cascata ma lo stavo facendo soltanto in un senso, cioè dai soggetti verso gli oggetti e mai dagli oggetti verso i soggetti, cosa che però è necessaria in un caso specifico ovvero quello in cui ci troviamo una risorsa nuova che non esiste all’interno del triplestore e che ha una venue che si esiste all’interno del triplestore e che quindi verrà deduplicata ma dato che volume e issue sono oggetti soltanto a partire dall’articolo e non a partire dalla venue, volume e issue non erano presenti nel grafo locale.
- Questa modifica ha portato i tempi necessari per ottenere tutti quanti i dati necessari dal Triple Store e metterli in locale da una manciata di secondi a svariati minuti. Questo perché la quantità di contenitori può esplodere notevolmente. Se bisogna recuperare tutti quanti i possibili contenitori per ogni contenuto è possibile dover processare anche decine di migliaia di risorse poi inutilmente perché quelle che servono realmente in locale sono molte meno. Pertanto soltanto per ricostruire gli alberi di Volumi, Venue e Issue ho deciso di ricorrere a Query SPARQL sul Triple Store e non in locale.
- Per quanto io sia riuscito a risolvere il problema della deduplicazione di volumi Venue Issue e accertare che il problema è risolto, tuttavia non sono riuscito a impedire nuove query SPARQL a ogni riprocessamento di dati già processati. Questa cosa avviene e continua ad avvenire perché, comunque, sul triplestore ci sono già dei volumi e delle Issue duplicate, quindi a ogni processamento è possibile che un articolo venga riassegnato a una diversa Issue o una Issue a un diverso volume. Questo comportamento, per quanto spiacevole, non è un bug e quindi non lo correggerò e tuttavia bisognerà correggere il problema a monte, ovvero la presenza di duplicate all’interno del triplestore per impedire che ciò avvenga.
- https://github.com/opencitations/oc_meta/issues/40
Aggiornata la documentazione nel README
GitHub Action per rilascio automatico di nuova versione su GitHub e PyPI con changelog automatico
Ho riscritto da zero la funzione che si occupa di generare i CSV a partire dai dati in RDF in maniera tale che si occupi soltanto della generazione dei CSV e non della modifica dei dati. Infatti lo script precedente era diventato troppo complesso e francamente impossibile da mantenere e da comprendere e non mi dava più garanzie di affidabilità perché sì è vero che era testato ma comunque il suo comportamento sui dati reali portava a degli aggiornamenti nei dati anche nel momento in cui veniva lanciato due volte sugli stessi dati in teoria già corretti. Per una questione di separazione delle responsabilità adesso c’è uno script che controlla i dati finali e uno script che genere i CSV di output e quest’ultimo è stato testato in ogni possibile aspetto.
- Attualmente, con 40 processi e la cache dei file aperti su singolo processo, è in grado di produrre i CSV di tutto il dump in 5 ore con un impatto sulla RAM relativamente contenuto (circa 10G)
Caricamento sul triplestore
- Ottimizzato utilizzando connection pooling. La stessa connessione viene riutilizzata anziché ricrearla ogni volta
- Prima veniva utilizzato un file JSON come cache. Adesso viene ancora utilizzato, però viene caricato su un Redis in maniera tale che vengano diminuite le operazioni di scrittura su file. I dati vengono poi riscritti sul file JSON in caso di processo interrotto tramite file di stop, tramite ctrl-c oppure interruzioni inaspettate del processo dovute a eccezioni, bug, crash, SIGTERM, SIGINT.
- Grazie a queste modifiche i tempi previsti per il caricamento della nuova versione di Meta sono passati da più di un migliaio di ore a un centinaio.
SKG-IF
- Aggiornato lo script per gestire la nuova organizzazione modulare dell’ontologia SKG-IF. Lo script ora è in grado di:
- Riconoscere automaticamente se sta lavorando con una versione precedente (che usa un singolo file) o con la nuova struttura modulare.
- Nel caso della nuova struttura, combinare correttamente tutti i moduli dell’ontologia per generare le SHACL shapes
- Mantenere la piena compatibilità con le versioni precedenti dell’ontologia
- Tutti i test che precedentemente fallivano con la nuova versione modulare dell’ontologia (1.0.1+) ora passano correttamente, in particolare:
- Problema: Codecov è molto figo ma richiede l’accesso all’organizzazione per essere configurato.
Soluzione: BYOB (Bring Your Own Badge)
- BYOB è un’action di GitHub che permette di creare badge dinamici basati sui risultati delle GitHub Actions. La particolarità di BYOB è che:
- Memorizza i dati del badge in un file JSON
- Permette di specificare dove salvare questi dati
- Ho creato un repository pubblico personale (arcangelo7/badges) che funge da contenitore per tutti i badge
- Configurato l’action per:
- Estrarre la percentuale di coverage dai test
- Generare un badge con nome univoco (skg-if-shacl-extractor_coverage)
- Salvare i dati nel repository personale usando un token personale
- Il badge viene aggiornato automaticamente ogni volta che i test vengono eseguiti sul branch main
1
2
3
4
5
6
7
8
9
10
11- name: Generate coverage badge
if: github.ref == 'refs/heads/main' && matrix.python-version == '3.9'
uses: RubbaBoy/BYOB@v1.3.0
with:
NAME: skg-if-shacl-extractor_coverage
LABEL: "Coverage"
STATUS: ${{ env.COVERAGE }}
COLOR: green
GITHUB_TOKEN: ${{ secrets.GIST_PAT }}
REPOSITORY: arcangelo7/badges
ACTOR: arcangelo7
- BYOB è un’action di GitHub che permette di creare badge dinamici basati sui risultati delle GitHub Actions. La particolarità di BYOB è che:
https://github.com/arcangelo7/badges/blob/shields/shields.json
oc_ds_converter
- Ho scritto dei test per verificare che il DOI-ORCID funzionasse per l’aggiunta di ORCID agli autori che non ce l’hanno per JALC e ho verificato che funzionava già
text2rdf
- https://github.com/monarch-initiative/ontogpt
- Esiste un software, OntoGPT, che utilizza un linguaggio chiamato LinkML, definito dagli stessi autori di OntoGPT, che permette, dato un testo, di ottenere in cambio dell’entità potenzialmente anche in RDF, anche se finora né io e Andrea siamo riusciti a ottenere RDF.
- I limiti finora incontrati di OntoGPT sono che LinkML rende obbligatoria la definizione di un albero di entità, che è inappropriato nel contesto di dati a grafo che non necessariamente hanno un albero.
- L’altro problema è la difficoltà nel definire lo schema, LinkML , perché appunto non è in un linguaggio standard, è in un linguaggio che uno deve imparare ad hoc e che è abbastanza semplice per named entity recognition ma complesso per RDF. Per RDF sarebbe più comodo poter utilizzare SHACL come linguaggio per la definizione dello schema.
Crowdsourcing
- Test automatici / release automatiche. Coverage 100%
- Revisione codice
- Quarta label: to be processed, diversa da done, Specificato meglio che rejected vuil dire non in safe list
- L’id dell’utente finisce nel was attributed to
- Ho integrato oc_validator
- Posso mettere una variabile d’ambiente su GitHub per dire se sono in ‘development’ o ‘production’. In development si carica sulla sandbox di Zenodo, in production su Zenodo vero e proprio.
- Le issue devonono essere marcate come deposit
- Report html perché quello testuale non è chiaro.
Domande
Sapevate che esiste questo: https://www.conventionalcommits.org/en/v1.0.0/?
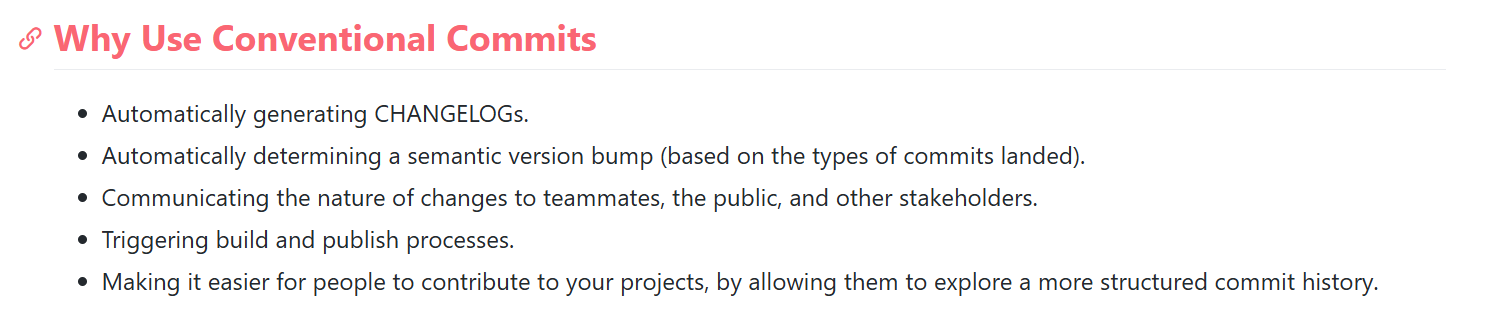
Quali identificativi accettiamo per il crowdsourcing?
- Pensavo doi|isbn|pmid|pmcid|url?|wikidata|wikipedia|openalex per le risorse bibliografiche e orcid|ror|viaf|crossref per i responsible agents.
- strict_sequenciality serve?
- Il feedback testuale non è chiaro
- Conta da 0
- CITS-CSV/META-CSV non sono chiari
- The value in this field → fields?
- Secondo me il report dovrebbe dire esplicitamente qual è l’errore
- Il primo elemento della lista di errori non ha lo spazio https://github.com/arcangelo7/crowdsourcing/issues/11
- The submitted table in file “temp_citations.csv” is not processable https://github.com/arcangelo7/crowdsourcing/issues/16
- self.strict_sequentiality al momento non fa nulla