2026-04-14 Devi portarmi la giustifica
La Novitade
Section titled “La Novitade”RAMOSE
Section titled “RAMOSE”
test: add tests for multi-source exec, OpenAPI export, and pluggable formats
refactor: split monolithic ramose.py into package modules
La documentazione non è aggiornata. Tanto vale copiare quello che c’è di buono ed estenderla nel solito sito Astro Starlight, così mentre scrivo capisco meglio le cose.
docs: migrate from Sphinx to Starlight and update documentation
refactor: remove allow_inline_endpoints gate
The @@endpoint directive now works unconditionally without requiring opt-in via #allow_inline_endpoints in spec files. The extra configuration added friction without meaningful safety benefit.
build!: migrate from setup.py to uv with pyproject.toml
Refactor get_config() to accept an explicit path instead of reading from ~/.opencitations/index/config.ini. Add --config CLI argument to every script entry point.
BREAKING CHANGE: all scripts now require --config flag pointing to the configuration file. The implicit ~/.opencitations/index/ convention and the setup.py that populated it are removed.
refactor!: restructure project from namespace package to standard layout
Move source from index/python/src/ to oc_index/, scripts from scripts/ to oc_index/scripts/, and tests from index/python/test/ to tests/. Switch build backend from setuptools to hatchling.
BREAKING CHANGE: the import path changes from oc.index to oc_index
Svolta della vita
Section titled “Svolta della vita”
https://docs.python.org/3/library/re.html#regular-expression-syntax
_DURATION_PATTERN = re_compile( r"P" r"(?:(?P<years>\d+)Y)?" r"(?:(?P<months>\d+)M)?" r"(?:(?P<days>\d+)D)?" r"(?:T" r"(?:(?P<hours>\d+)H)?" r"(?:(?P<minutes>\d+)M)?" r"(?:(?P<seconds>\d+(?:\.\d+)?)S)?" r")?")
class _ISODuration(NamedTuple): years: int months: int remainder: timedelta
def _parse_duration(duration_str: str) -> _ISODuration: duration_match = _DURATION_PATTERN.fullmatch(duration_str) parts = {key: value or "0" for key, value in duration_match.groupdict().items()} return _ISODuration( years=int(parts["years"]), months=int(parts["months"]), remainder=timedelta( days=int(parts["days"]), hours=int(parts["hours"]), minutes=int(parts["minutes"]), seconds=float(parts["seconds"]) ) )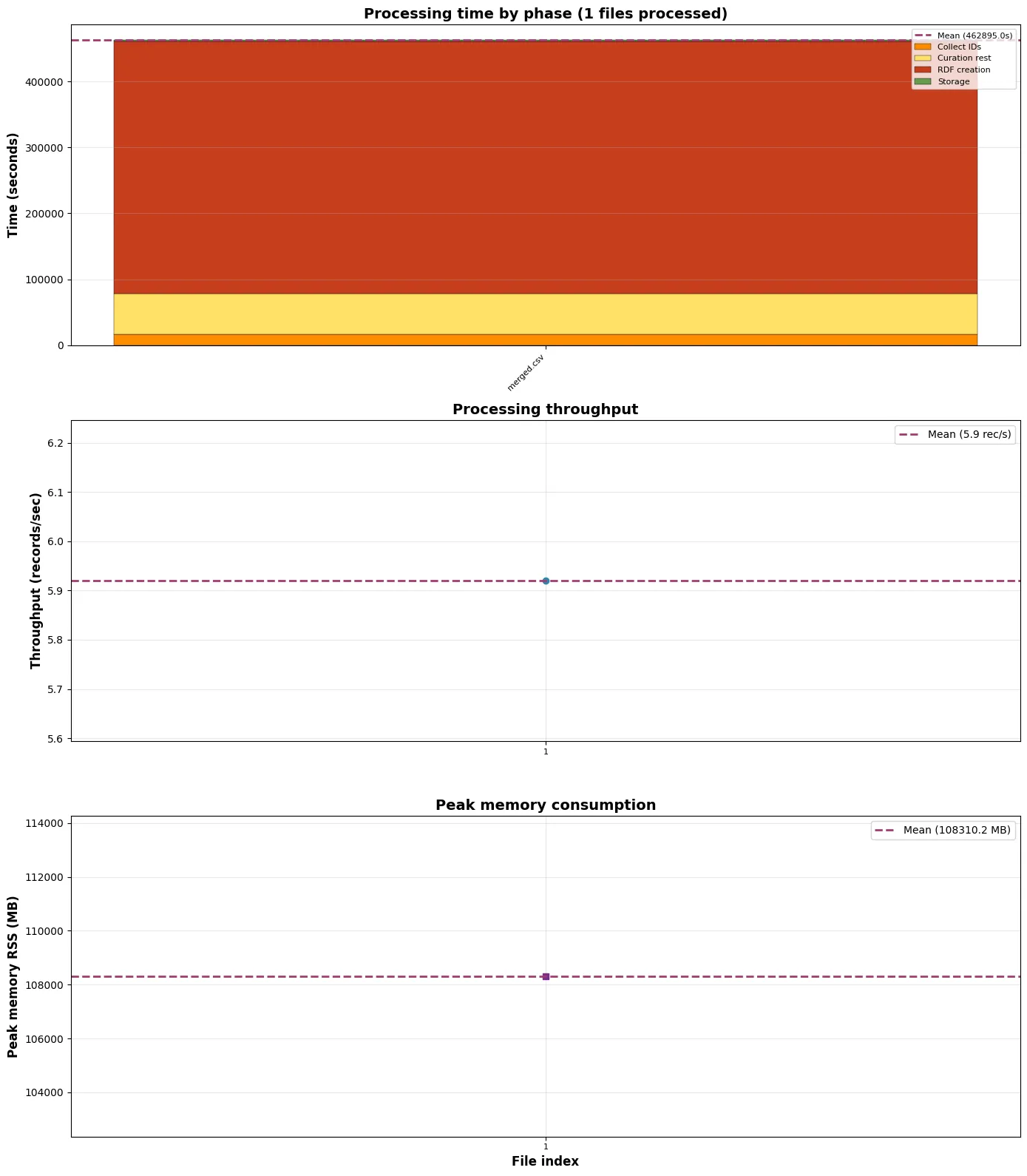
============================================================Aggregate Timing Summary============================================================Total Files: 1Total Duration: 460676.125s (5,3 giorni)Total Records: 2_728_607Total Entities: 43_778_738Overall Throughput: 5.92 rec/sPeak Memory (RSS): 108310.2 MB (108 GB)Avg Peak Memory: 108310.2 MB============================================================Perché esportare in nquads per indicizzare in Qlever? Si possono indicizzare direttamente i file RDF JSON-LD compressi, visto che Qlever prende in input un comando shell che ritorna testo per capire cosa indicizzare.
Ah no, Qlever non supporta JSON-LD. Posso comunque convertire in streaming, in un solo passaggio e senza occupare TB sul disco per niente.
Flag -f: The file with the knowledge graph data to be parsed from. If omitted, will read from stdin.
Potremmo fare
CAT_INPUT_FILES | qlever-index -F nq -f -uv run python --project "${OC_META}" -m oc_meta.run.migration.stream_nquads "${RDF_DIR}" --mode data --workers "${WORKERS}" | \docker run -i --entrypoint qlever-index "docker.io/adfreiburg/qlever:commit-5c6a72a"-F nq -f -feat(migration): add stream_nquads tool
stream_nquads streams N-Quads from JSON-LD ZIPs to stdout via multiprocessing, designed to pipe directly into QLever's indexer without intermediate files.
https://openreview.net/forum?id=XUc9rtTsHp
Mi hanno accettato l’RML paperazione. Voti meh. In sintesi: ottima metodologia, ma quello che stai cercando di fare non serve a niente. Ha ricevuto scarso interesse finora perché è scarsamente interessante. Ci sta. Non mi è mai piaciuto Sanremo.
La conferenza si svolgerà a Dubrovnik, Croatia tra il 10 e l’11 maggio (https://kg-construct.github.io/workshop/).
Domande
Section titled “Domande”RAMOSE
Section titled “RAMOSE”-
Gli elementi specifici di Ramose che non hanno un equivalente in OpenAPI vengono messi in un unico oggetto in fondo allo YAML generato. Ma secondo me nel contesto di OpenAPI non hanno alcun senso perché sono dettagli implementativi.
x-ramose:preprocess: lower(dois) --> split_dois(dois)call: /metadata/10.1108/jd-12-2013-0166__10.1038/nature12373sparql_in_description: truecall, tra l’altro, viene già mappato nel campo example di OpenAPI. sparql_in_description invece è inventato ed è un mistero. Io toglierei tutto questo blocco.
-
Per #method il default su POST è sbagliato, secondo me. È un hack e non sempre funziona. Ad esempio, Qlever non permette i SELECT con POST.
-
Al momento gli unici formati supportati nativamente sono CSV e JSON. XML può essere aggiunto come formato custom grazie alle modifiche di Sergei. Ma XML non è un formato custom, è un formato standard, dovrebbe essere gestito di default, no?
Filter sul pre-processing
Section titled “Filter sul pre-processing”Io lo farei così
[...]
#url /products#type operation#method get#custom_params filter,handle_skgif_filter,SKG-IF filter parameter. Syntax: field:value pairs separated by comma.#call /products?filter=title:semantics#format skgif,to_skgif[...]La riga nuova è #custom_params. Segue lo stesso pattern di #format: nome,funzione_handler,descrizione separati da ; se ce ne sono più di uno. Il contro è che questo filter andrebbe a sovrascrivere il filter standard di RAMOSE, ma quello è inevitabile, non vedo un modo sensato per usare la stessa parola per fare due cose diverse.
Insisto sul fatto che il formato HF sia difficile da leggere e che utilizzare la libreria YAML di Python annullerebbe il problema di parsing di file YAML, che non andrebbero parsati a mano. Tra l’altro, YAML è già una dipendenza di RAMOSE, dato che produciamo lo YAML di OpenAPI. Da questo punto di vista si potrebbe utilizzare direttamente il linguaggio di OpenAPI per produrre API REST su SPARQL Endpoint, eliminando completamente il formato HF. Questo avrebbe il vantaggio di estendere la semantica di un linguaggio ben noto, di uno standard, un po’ come abbiamo fatto per SHACL in HERITRACE, senza la necessità che uno impari da zero un nuovo formato.
Nella pratica quotidiana di uno sviluppatore si utilizza un editor che evidenzia la sintassi dei linguaggi che utilizza. Ovviamente il formato HF non ha nessun tipo di evidenziazione o di segnalazione automatica degli errori, cosa che invece c’è per YAML. Per rendere più utilizzabile il formato HF bisognerebbe creare un’estensione di Visual Studio Code che aggiunga il syntax highlighting.
Ambiguità di @@values
Section titled “Ambiguità di @@values”@@values ?var1 ?var2 → inietta SPARQL VALUES nella query successiva
@@values ?var:alias → dichiara un alias per un’iterazione @@foreach
Schema generale: @@direttiva <arg_obbligatori…> [modificatore | chiave valore]…
@@with index @@join ?doi ?id left
@@foreach ?br wait 0.1
Anziché
@@values ?br:a @@foreach a 0.1
Estensibile
@@foreach ?br wait 0.1 batch 50 @@join ?doi ?id left normalize off (per disattivare la normalizzazione http/https che il join fa di default sulle chiavi)
Problema, con questa sintassi non c’è modo di sapere se normalize è un secondo modificatore singolo o la chiave di off.
Bisogna rendere tutto chiave-valore
@@join ?doi type left anziché @@join ?doi left
@@direttiva <arg_obbligatori…> [chiave valore]
oc_ocdm
Section titled “oc_ocdm”sostituirei Dataset con questo
class RDFTerm(NamedTuple): type: str value: str datatype: str = ""
Triple = tuple[str, str, RDFTerm]SPOIndex = dict[str, dict[str, set[RDFTerm]]]
class LightGraph: __slots__ = ("_spo", "_triples", "identifier")
def __init__(self, identifier: str | None = None) -> None: self._spo: SPOIndex = {} self._triples: set[Triple] = set() self.identifier: str | None = identifierContinuerei a usare rdflib solo per parsare RDF in input e scriverne in output.
Il codice scritto da Giuseppe non viene usato da nessuna parte nel codice di Index, vi risulta?
Dubrovnik
Section titled “Dubrovnik”Io seguo solo il workshop, giusto? Non ESWC. Anche perché significherebbe acquistare un (immagino costoso) biglietto d’ingresso senza presentare nulla. Quindi: arrivo il 9 e riparto il 12? Posso usare i fondi di GRAPHIA?