12-04-2022 Meta piantata
Cosa ho fatto
- Novità relative a Meta:
- Se un volume viene spostato dal campo “issue ” al campo “volume” o viceversa e il tipo di risorsa è “journal volume” o “journal issue”, allora anche il tipo viene modificato e invertito.
- Ho aggiunto dei test per verificare l’output di Meta in multiprocess.
- In multiprocess, Meta non processa più i file di input in chunk, ma lavora a ciclo continuo. Una volta finito un file passa al successivo, senza aspettare che tutti gli altri file del chunk siano stati processati. In questo modo, tutti i processi rimangono operativi e non dormienti.
- Se un id compare più di una volta all’interno del campo “id”, o in un campo “venue” compare un id già incontrato in un campo “id”, allora quell’id viene pre-processato:
- Viene processato solo l’id duplicato, non tutti gli id associati alla risorsa. Sarà Meta in un secondo momento, a partire dal MetaID, ad aggiungere tutti gli altri id, laddove presenti.
- Viene processato solo il campo “id”. Tutti gli altri campi verranno popolati da Meta a partire dal MetaId.
- Perché non processare immediatamente tutta la riga? Perché occorrerebbe preprocessare circa 1,3 GB di dati, che richiederebbe troppo tempo senza che ce ne sia la necessità.
- Ho cominciato a lavorare all’integrazione di time-agnostic-library con Apache Jena Fuseki:
Ho risolto il problema discusso nel seguente blocco: Ti risulta che utilizzando il Fuseki le query vengano eseguite solo sul grafo di default? Sai come configurarlo in modo che le query vengano eseguite di default sull’unione dei grafi?
Occorre specificare il parametro
tdb2:unionDefaultGraph truenel file di configurazione:1
2
3
4
5
6
7@prefix tdb2: <http://jena.apache.org/2016/tdb#> .
@prefix ja: <http://jena.hpl.hp.com/2005/11/Assembler#> .
tdb2:DatasetTDB2 rdfs:subClassOf ja:RDFDataset .
:tdb_dataset_readwrite
rdf:type tdb2:DatasetTDB2 ;
tdb2:location "path/to/data" ;
tdb2:unionDefaultGraph true.Anche Fuseki usa Lucene per costruire l’indice testuale. Tuttavia, a differenza di GraphDB, non è necessario specificare il nome dell’indice o del connector nella query. È sufficiente utilizzare il predicato
text:query, similmente a quanto avviene per Blazegraph conbds:search.Rispetto a Blazegraph, Fuseki permette di creare più indici per predicati diversi, ma basta specificare che la query avviene su oco:hasUpdateQuery e Lucene la esegue sull’indice giusto.
Ho aggiunto un nuovo parametro di configurazione a time-agnostic-library,
fuseki_full_text_search, speculare ablazegraph_full_text_search, che accetta un valore booleano.
Domande
- Sapete se Apache Jena Fuseki metta a disposizione un indice testuale generale nel quale siano indicizzati indistintamente tutti i letterali?
Cosa ho fatto
- Novità relative a Meta:
Se un volume viene spostato dal campo “issue ” al campo “volume” o viceversa e il tipo di risorsa è “journal volume” o “journal issue”, allora anche il tipo viene modificato e invertito.
Ho aggiunto dei test per verificare l’output di Meta in multiprocess.
In multiprocess, Meta non processa più i file di input in chunk, ma lavora a ciclo continuo. Una volta finito un file passa al successivo, senza aspettare che tutti gli altri file del chunk siano stati processati. In questo modo, tutti i processi rimangono operativi e non dormienti.
Se un id compare più di una volta all’interno del campo “id”, o in un campo “venue” compare un id già incontrato in un campo “id”, allora quell’id viene pre-processato:
- Viene processato solo l’id duplicato, non tutti gli id associati alla risorsa. Sarà Meta in un secondo momento, a partire dal MetaID, ad aggiungere tutti gli altri id, laddove presenti.
- Viene processato solo il campo “id”. Tutti gli altri campi verranno popolati da Meta a partire dal MetaId.
- Perché non processare immediatamente tutta la riga? Perché occorrerebbe preprocessare circa 1,3 GB di dati, che richiederebbe troppo tempo senza che ce ne sia la necessità.
Ci sono stati nuovamente problemi di RAM, questa volta causati dal Creator e dalla generazione della provenance. Ecco come li ho aggirati:
- Ho delegato ai processi figli e non al processo genitore il salvataggio dei dati e della provenance su file e triplestore. In questo modo, ogni processo deve smaltire i propri dati prima che venga generato un ulteriore processo. In precedenza, i dati da salvare venivano messi in coda nel processo genitore, accumulandosi indefinitivamente.
- I dati vengono sempre salvati in sequenza, ma tramite lock nei processi figli e non tramite coda nel processo genitore.
- Nelle condizioni attuali, utilizzare 11 processi (10+1) consuma circa 34 su 67G. Considerando anche gli altri processi attivi, tra cui 4G per il triplestore, mi è capitato di vedere appena 2G liberi su oc_ficlit.
Devo rivedere molto al ribasso le stime sul tempo previsto in multi-processing.
Dopo la preparazione al multiprocessing, Meta parte da un triplestore che pesa 12G contenente 69,361,978 di triple. In questo triplestore sono già presenti tutti gli autori, tutti i publisher e le venue.
Recuperare entità preesistenti per Meta è più dispendioso che crearne di nuove. Inoltre, lavorare su un triplestore più grande rende le query più lente, dato che molte si fondano sul cercare identificatori a partire dal valore letterale.
Il tempo stimato attuale, dopo 12 ore di esecuzione con 5 processi (4+1), è di 14,000 ore, ovvero 19 mesi. Sono stati processati appena 19 file su 39,997.
Il paradosso è che, date queste condizioni, il single-process è molto più rapido del multi-process, perché per preparare il multi-process occorre costringere Meta a recuperare entità già esistenti e ad andare molto più lentamente.In single-process oc_ficlit ha processato 19 file in 54 minuti anziché 12 ore e il tempo stimato è di 1990 ore, ovvero circa 3 mesi.Si potrebbe pensare che questo sia il migliore scenario e che non sia indicativo di come Meta opererà tra svariate settimane, ma non è così. Crossref salva negli stessi file dati relativi a entità simili, spesso perché hanno la stessa casa editrice. Pertanto, è più probabile trovare entità ripetute in file vicini che lontani.Operare in single-process ha un altro vantaggio: rende estremamente improbabile che il processo si interrompa durante la generazione dei file RDF o il caricamento sul triplestore (cfr. Figura 1). Infatti, Meta crasha solo se incontra un caso imprevisto nel dump, quindi durante il Curator. Tuttavia, se si opera in multi-process, è assai probabile che, mentre un processo crasha durante il Curator, un altro stia già salvando i dati.
Il grafico in Figura 1 mostra gli output dei vari passaggi del software di Meta e se un crash durante la loro generazione crei incongruenze tra i file e il triplestore.
- Curator → CSV temporanei, log, indici, info_dir
- Un crash non crea incongruenze tra triplestore e file
- Creator → graphset
- Un crash non crea incongruenze tra triplestore e file
- ProvSet → provenance
- Un crash crea incongruenze tra triplestore e file
- Storer → RDF, triplestore
- Un crash crea incongruenze tra triplestore e file
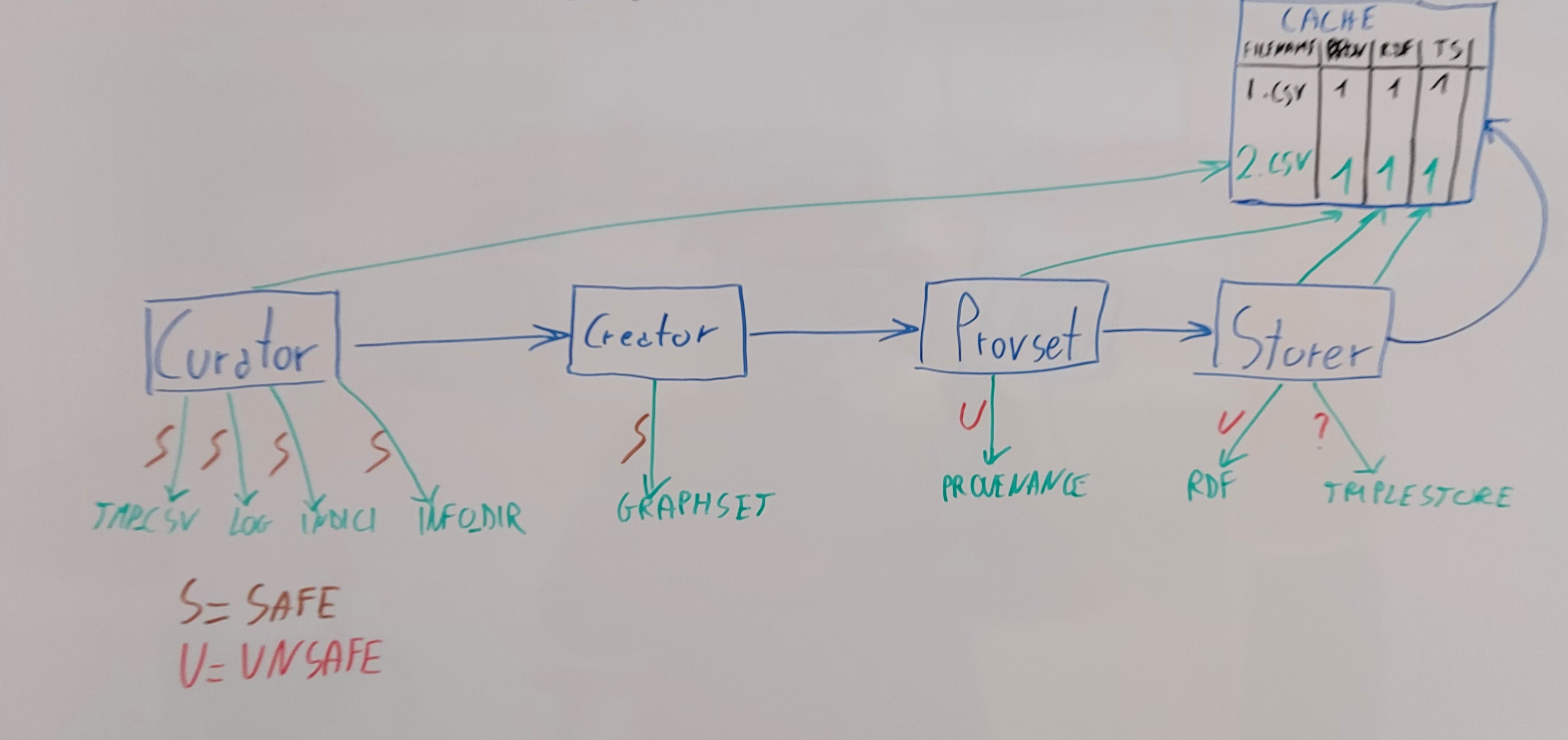
Figura 1. Workflow del software di Meta. Ogni passaggio riporta i relativi output e se un crash durante la loro generazione crei incongruenze tra i file e il triplestore.
- Curator → CSV temporanei, log, indici, info_dir
Risolto un bug devastante in crossref_processing, che si verifica quando due coautori hanno lo stesso cognome e la stessa iniziale del nome (e.g. http://doi.org/10.1001/2012.jama.11061).
- A entrambi viene assegnato lo stesso ORCID e diventano uno l’autore successivo dell’altro, generando un loop infinito.
- Il bug si risolve imponendo come condizione che, se ci sono più autori con lo stesso cognome e la stessa iniziale del nome, l’ORCID va assegnato alla persona in cui nome case insensitive matcha perfettamente con il nome registrato su ORCID.
- Ho cominciato a lavorare all’integrazione di time-agnostic-library con Apache Jena Fuseki:
Ho risolto il problema discusso nel seguente blocco: Ti risulta che utilizzando il Fuseki le query vengano eseguite solo sul grafo di default? Sai come configurarlo in modo che le query vengano eseguite di default sull’unione dei grafi?
Occorre specificare il parametro
tdb2:unionDefaultGraph truenel file di configurazione:1
2
3
4
5
6
7@prefix tdb2: <http://jena.apache.org/2016/tdb#> .
@prefix ja: <http://jena.hpl.hp.com/2005/11/Assembler#> .
tdb2:DatasetTDB2 rdfs:subClassOf ja:RDFDataset .
:tdb_dataset_readwrite
rdf:type tdb2:DatasetTDB2 ;
tdb2:location "path/to/data" ;
tdb2:unionDefaultGraph true.Anche Fuseki usa Lucene per costruire l’indice testuale. Tuttavia, a differenza di GraphDB, non è necessario specificare il nome dell’indice o del connector nella query. È sufficiente utilizzare il predicato
text:query, similmente a quanto avviene per Blazegraph conbds:search.Rispetto a Blazegraph, Fuseki permette di creare più indici per predicati diversi, ma basta specificare che la query avviene su oco:hasUpdateQuery e Lucene la esegue sull’indice giusto.
Ho aggiunto un nuovo parametro di configurazione a time-agnostic-library,
fuseki_full_text_search, speculare ablazegraph_full_text_search, che accetta un valore booleano.
Domande
- Quando Meta partirà sul server principale di OpenCitations io avrò modo di controllare il processo, in modo da correggere errori imprevisti e farlo ripartire? Al momento, Meta crasha solo a causa di casi esoterici nel dump di Crossref, che non sono prevedibili e, allo stesso tempo, non sono un problema, perché un crash durante il Curator non crea incongruenze tra il triplestore e i file.