21-06-2022 It’s outreach time
Cosa ho fatto
OC Meta e le sue apette
- OC Meta ha processato 11,000/66,000 file CSV senza errori a me noti (≃17%).
- Sto lavorando all’API per oc-meta. Ho abbozzato l’operazione che, data una lista di identificatori, restituisce i metadati delle risorse corrispondenti.
Divulgazione
Ho preparato la presentazione del demo paper per ULITE-ws
- Link per vedere e commentare: https://docs.google.com/presentation/d/1jOnZotk9bBRAb4cP-vFqBqf76aD4zd0Gh92OchFnQ8s/edit?usp=sharing
Ho realizzato il poster per ISWS. Presenterò il sistema di provenance dell’OCDM e time-agnostic-library:
Riflessioni sulla letteratura intorno alle time-traversal queries
Towards Fully-fledged Archiving for RDF Datasets sostiene che R&WBase (Ruben Verborgh è tra gli autori) supporti tutte le query temporali live, a differenza di quanto io avessi dedotto leggendo l’articolo che ne parla.
- Ammettendo che ciò sia vero, R&WBase ha dei limiti rilevanti rispetto a time-agnostic-library:
- È strettamente dipendente dal triplestore utilizzato. Al momento, necessita o di Fuseki o di Virtuoso per funzionare.
- Non è mai andato oltre la proof of concept e manca di documentazione, come detto da uno degli autori in una issue su GitHub. Dato che l’ultimo commit è del 2014, R&WBase può essere considerato un progetto rimasto tale.
- Non è un approccio totalmente semantico, necessita di tabelle di hash per funzionare.
- Ammettendo che ciò sia vero, R&WBase ha dei limiti rilevanti rispetto a time-agnostic-library:
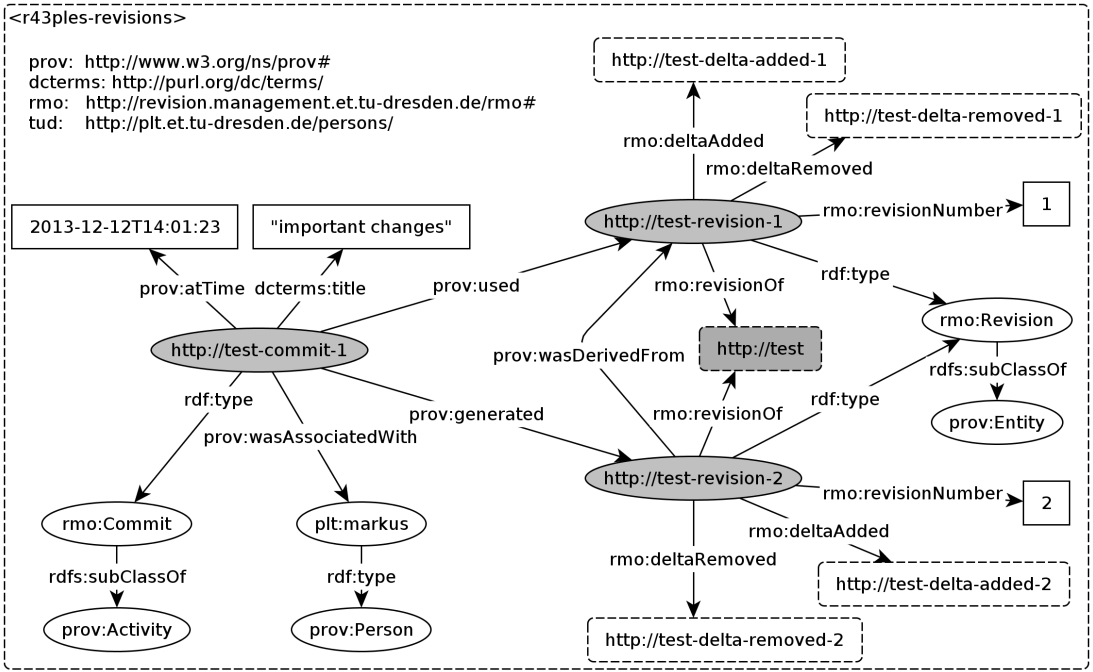
R43ples si ispira a R&WBase e lo perfeziona.
- Miglioramenti:
Supporta tutte le query temporali live.
È una soluzione totalmente semantica
The whole approach uses semantics in order to avoid hidden
meanings which makes it hard for other clients to access the
information
- Limiti:
- Usa un modello incompatibile con RDF e SPARQL, perché si basa su quintuple e aggiunge varie operazioni a SPARQL (TAG GRAPH, REVISION, BRANCH, MESSAGE).
R43ples è un proxy, un interprete tra due triplestore, uno contenente i dati e l’altro change tracking + provenance

- Usa un modello incompatibile con RDF e SPARQL, perché si basa su quintuple e aggiunge varie operazioni a SPARQL (TAG GRAPH, REVISION, BRANCH, MESSAGE).
- Note:
R43ples salva le revisioni come named graph
Il data model usa usa PROV-O + {rmo:revisionOf, rmo:revisionNumber, rmo:deltaAdded, rmo:deltaRemoved, rmo:references}. Si chiama Revision Management Ontology (RMO).
- Miglioramenti:
TailR utilizza una strategia di archiviazione ibrida (IB/CB). Utilizza tabelle di hash per rendere più efficienti le query. Ciononostante, le tabelle vengono aggiornate in tempo reale.
Q1 What was the description RDFx of URIx at time t?
Q2 When did the description for URIx change?
Q3 Which URI∗ existed at time t?Other, high-level queries like cross-version queries may be
implemented in terms of these basic classes of queriesQ1 è una VM, Q2 è DM, Q3 è l’inverso di una VQ da cui è ricavabile una VQ.
- Non usa SPARQL per effetturare le query, ma il protocollo Memento, ovvero la content-negotiation di HTTP tramite l’header
Accept-Datetime
- Non usa SPARQL per effetturare le query, ma il protocollo Memento, ovvero la content-negotiation di HTTP tramite l’header
| Software | Storage paradigm | Queries | Live | Fully semantic, compliant with RDF and SPARQL | Source available | Year (serve solo a me per mettere in ordine i software) | Strategia | Database-agnostic |
|---|---|---|---|---|---|---|---|---|
| SemVersion | IC | VM,DM | + | - b | - | 2005 | Middleware | + |
| x-RDF-3X | TB | VM, V | + | - | + | 2010 | Custom database | - |
| RBDMS | CB | all | - | - cd | - | 2012 | Relational database | - |
| R&WBase | CB | all | + | - c | + | 2013 | Middleware (only for Fuseki and Virtuoso) | - |
| R43ples | CB | all | + | + | + | 2014 | Middleware | - |
| TailR | IC/CB | VM,VQ,CV,CM | + | - cd | + | 2015 | Middleware | + |
| Dydra | TB | all | - | - ab | - | 2016 | Custom database | - |
| RDF-TX | TB | all | - | - a | - | 2016 | Custom database | - |
| v-RDFCSA | TB | VM, DM, V | + | + | - | 2016 | Custom database | - |
| OSTRICH | IC/CB/TB | all | - | + | + | 2018 | Custom database | - |
| QuitStore | FB | all | + | - a | + | 2019 | Middleware | - |
| time-agnostic-library | CB/TB | all | + | + | + | 2022 | Middleware | + |
- It extends SPARQL
- It extends RDF
- It requires hash tables
- It doesn’t use SPARQL to perform queries
Domande
Domande su Ramose
- Facciamo un brainstorming sulle operazioni da abilitare per l’API di OCMeta?
- Il file di configurazione di RAMOSE accetta due valori per
type,apieoperation. In tutti i file di esempio il valore dimethodper quanto riguarda l’apiè semprepost. Perché? - A titolo di esercitazione, ho creato l’operazione
metadata/{ids}, che dato un identificatore restituisce tutti i metadati connessi. Dovrei validare il valore diids? - Non so come gestire la sintassi
schema:valuedegli identificatori tramite Ramose. Da quello che ho capito, i valori in input di un’operazione possono essere preprocessati, ma vengono comunque interpolati tramite un’unica variabile all’interno della query SPARQL. Non so come spacchettare la variabile relativa allo schema da quella relativa al valore.- Anche spacchettando le due variabili, in SPARQL posso usare solo l’operatore VALUES per gestire liste di valori, che non preserva l’accoppiamento tra schemi e valori letterali degli identificatori.
- Dovrei creare operazioni separate per schemi diversi? Ad esempio, un operazione
metadata-from-dois/{DOI_LIST},metadata-from-pmid/{PMID_LIST},metadata-from-issn/{ISSN_LIST}.
- Il formato
.hfsupporta i commenti?
Domande su time-agnostic-library
- Cosa dovei intendere per “live”? La presenza di un indice non implica un sistema non live. Ad esempio, x-RDF-3X usa degli indici, ma li aggiorna in tempo reale, senza interrompere il servizio. In un certo senso, come ci ha fatto notare il terzo revisore, anche time-agnostic-library usa degli indici, ovvero quelli dei triplestore.
- È corretto dire che time-agnostic-library e OCDM utilizzano un sistema totalmente semantico e compatibile con RDF e SPARQL per gestire provenance e tracciamento dei cambiamenti?
- OCDM non estende RDF
- time-agnostic-library non estende SPARQL e usa SPARQL per le query
- I dati vengono salvati in modo totalmente semantico, senza tabelle di hash
Tuttavia, serve Python per colmare le mancanze di SPARQL che non permette di esprimere intervalli temporali, quindi anche time-agnostic-library potrebbe essere considerato non totalmente semantico. Sbaglio?
Domande sulla conferenza ULITE

- Do we miss anything else that I can add to the list?
- In che modo caricare i dati citazionali su Figshare/Zenodo indicando l’ORCID dell’agente responsabile impedisce fenomeni di manipolazione dei dati e gaming? Io potrei caricare quello che voglio su Zenodo con un account farlocco e indicare un ORCID a caso, sbaglio?
Note
- La documentazione di Ramose non specifica che le funzioni di postprocess devono ritornare una tupla, dove il secondo elemento è un booleano che specifica se aggiungere o meno il tipo dei valori nel risultato. Questa informazione andrebbe aggiunta.
In generale, sarebbe utile avere un esempio di funzione di preprocess e di postprocess. Ho avuto bisogno di spulciare nel codice di Ramose per capire come strutturarle. Ad esempio
1
2
3
4# Preprocess function example
def split_ids(s):
return "\"%s\"" % "\" \"".join(s.split("__")),