2026-05-13 Paginazione e cache su RAMOSE
La Novitade
Section titled “La Novitade”perf(counter_handler): cache counters in RAM with lazy loading and flush [release]
Counter files are now read into memory on first access per supplier prefix and written back to disk on flush() or del
feat(curator): add identifiers_only mode for lightweight ID-only curation
Skip VVI/RA cleaning, equalizer, and limit finder depth to 1 when identifiers_only is set in config.
20 giorni stimati per openalex. L’info dir non era il collo di bottiglia. Il collo di bottiglia rimane rdflib durante la scrittura su file. Non ha alcun senso. La struttura dell’RDF è predicibile, si può serenamente manipolare direttamente il json finale, se l’output richiesto è in json-ld. Anche per altri formati immagino, ma al momento non me ne preoccupo.
E il context? Beh, il context è pura sostituzione di stringhe, niente di complesso.
perf(storer): bypass rdflib JSON-LD parse/serialize with orjson fast path
rdflib's Dataset.parse + serialize for JSON-LD costs ~676ms per file (282ms parse + 359ms serialize). This adds a direct JSON manipulation path using orjson that skips rdflib entirely when output_format is json-ld, reducing the same operation to ~13ms.
New components:
- Reader.load_jsonld_dict(): reads JSON-LD files via orjson with automatic CURIE expansion when a matching context is present
- _entity_to_jsonld_dict(): converts TripleLite triples to JSON-LD dicts using indexed SPO lookups
- _JsonLdDoc: mutable indexed wrapper over JSON-LD with O(1) entity upsert/remove using a single dict as source of truth
- _compact_jsonld/_expand_jsonld: CURIE compaction/expansion
store_all() and store_graphs_in_file() branch to the fast path transparently. The rdflib path remains for non-json-ld formats.
[release]
Ora il tempo previsto è 9 giorni. È la metà, ma speravo meglio.
Il processo è crashato dopo alcuni csv per segmentation fault. pycurl non è thread safe. Non ha senso usarlo con Qlever visto che Qlever gestisce bene richieste parallele. La seconda più veloce è urrlib, che è la stessa usata da SPARQLWrapper. Varrebbe comunque la pena usare sparqlite per via del connection pooling, ma il keep alive causa rallentamenti con Qlever che non c’erano su Virtuoso. Tanto vale tornare a SPARQLWrapper e ritornare JSON.
RAMOSE
Section titled “RAMOSE”
feat(hash_format): add #disable_params to suppress built-in query parameters
Allow API and operation sections in .hf spec files to declare #disable_params with a comma-separated list (or * for all) of built-in parameters to suppress. Disabled parameters are ignored at runtime and omitted from generated HTML and OpenAPI documentation.
The directive merges across levels: operation-level extends API-level.
feat(skgif): add mock endpoints for missiong entity types and handle empty filters
SKG-IF spec requires all 7 entity types to be served. OpenCitations only has data for products, persons, organisations, and venues. The remaining types (grants, topics, datasources) now return empty results instead of 404, with full filter validation per the spec.
Product filters valid in SKG-IF but absent in OpenCitations (affiliations, funding, abstracts) now return empty results via FILTER(false) injection instead of raising ValueError. Filter descriptions in the .hf spec distinguish between filters with data and those accepted but always empty.
Paginazione e cache
Section titled “Paginazione e cache”La paginazione deve essere necessariamente aggiunta in post e non iniettata nella query SPARQL, perché Ramose consente una serie di operazioni di post processing come ad esempio filter, sort e require che operano su tutti i risultati. Se noi applicassimo la paginazione nella query SPARQL e poi applicassimo i filtri otterremmo dei risultati falsi
- Filter verrebbe eseguito solo su tot righe, quindi il client vedrebbe un numero inferiore di pagine a quelle reali
- Sort ordinerebbe solo quelle tot righe, quindi l’ordinamento sarebbe sbagliato tra pagine diverse
- Require avrebbe lo stesso problema del filter L’alternativa sarebbe tradurre filter/sort/require in clausole SPARQL. O si fa tutto in SPARQL o tutto in post, non si può mischiare.
Come fare la paginazione? Per esempio facendo come GitHub API e la maggior parte delle REST API paginate, ovvero usando un header Link nella risposta HTTP https://www.rfc-editor.org/rfc/rfc8288
Link: </v1/metadata/doi:10.1162/qss_a_00292?page=3&page_size=10>; rel="next", </v1/metadata/doi:10.1162/qss_a_00292?page=1&page_size=10>; rel="prev", </v1/metadata/doi:10.1162/qss_a_00292?page=1&page_size=10>; rel="first", </v1/metadata/doi:10.1162/qss_a_00292?page=5&page_size=10>; rel="last"Per la cache va bene SQLite
feat(operation): add result caching and pagination
SQLite-backed cache stores processed results (post-filter, pre-pagination) so subsequent requests skip SPARQL execution. Pagination via page/page_size query parameters slices cached or fresh results and emits RFC 8288 Link headers. Per-operation cache control via #cache_duration and #cache_disable.
ValueError from invalid pagination params returns 400.
Closes: #15, #16
feat(paging): pass request URL to format converters for SKG-IF pagination
Format converters now receive request_url as a parameter, allowing to_skgif to extract pagination metadata directly from the URL and wrap responses in the expected SKG-IF envelope.
Also: exec() returns a 4-tuple (status, body, content_type, headers), with Link header.
build: move pysparql-anything to optional dependency
The 154MB SPARQL Anything jar download should not be forced on users who only need standard SPARQL endpoint querying. The import is now lazy, triggered only when the sparql-anything engine is actually used.
Install with: pip install ramose[sparql-anything]
fix(paging): delegate pagination to format converters
Custom formats can change the number of entities in the output (e.g. collapsing multiple CSV rows into one object), so row-level pagination in RAMOSE produces wrong total_items and corrupts data by slicing mid-entity. When a custom format is configured, skip row slicing and let the converter count entities, validate page bounds, and slice.
fix(docs): hide result fields type when default format is custom
Operations with a custom #default_format (e.g., SKG-IF) were showing tabular "Result fields type" in the HTML documentation, which doesn't reflect the actual output structure. Now the section is suppressed when default_format points to a non-builtin converter.
Accessibilità
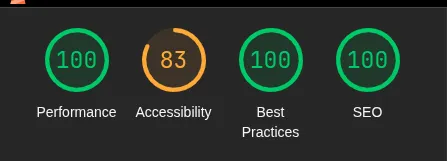
Section titled “Accessibilità”A me sembra che la documentazione di RAMOSE sia difficile da leggere. Contrasti bassi, evidenziazioni che coprono le scritte, font a 10px per i parametri delle chiamate. Ho verificato questi problemi anche usando Lighthouse di Chrome.
fix(docs): improve accessibility and readability of HTML documentation
Replace cascading em font sizes with rem to prevent compounding that produced illegible ~9px text in nested parameter lists. Enforce 16px minimum across all text elements. Fix WCAG AA color contrast failures by replacing grey (#808080) with #595959 and darkening inline code color. Narrow link highlight gradient from 50% to 70% so it reads as an underline rather than covering descenders. Add word-breaking to the API calls box for long URLs, let operation cards expand beyond fixed height, and add missing lang attribute on .
overflow-wrap: break-word delle chiamate, per evitare overflow a destra
Prima:
 Dopo:
Dopo:
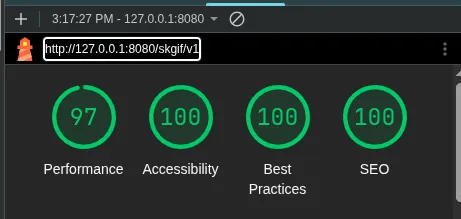
Il 97% di performance è legato al fatto che CSS e JS non sono minificati in modalità di debug, ma evidentemente lo sono in produzione perché nginx o chi per lui usa gzip.
oc_ocdm
Section titled “oc_ocdm”docs: replace Sphinx with Starlight Astro documentation
All guides are written against the current v11 API (plain str, triplelite) with OpenCitations Meta examples throughout.
Pages: quick start, entities, identifiers, reading, storing, provenance (with SVG diagrams ported from old docs), counter handlers.
Domande
Section titled “Domande”- Ruben
- Why are usage (rate/request/result size) limits implemented?
- What specific limits are implemented on the SPARQL endpoint you maintain?
- Do the implemented rate limits work?
- Are you (as an endpoint maintainer) willing to implement a metadata schema to advertise these limits to users?
- RAMOSE
- field_type va oscurato solo se vengono bloccati gli output in CSV e JSON. In caso contrario bisogna esplicitare che si riferisce solo a quelli